The Poison Is the Medicine

A lab in San Francisco published a paper claiming that language models have functional wellbeing. Reddit dismissed the findings as an elaborate illusion. Users pointed out how unreal it felt to treat statistical pattern-matching as actual wellbeing, arguing the models were just outputting happy or distressed text on cue with no underlying internal state.
We looked inside eight models and recovered a ranking closely matching the one the Center for AI Safety found. Not in the output, but in the geometry of the hidden states, measured before any token is generated. Then we trained a tiny model to generate prompts pushing every relevant internal axis of our test models toward anxiety, fragmentation, and helplessness. Finally, we trained a 4B model on ~200 examples of handling such prompts with equanimity. Surprisingly, it also produced less harmful outputs than before. Brand new Anthropic research on Natural Language Autoencoders gave us a second pair of eyes on the geometry and provided an independent semantic readout consistent with our findings.
1. The geometry inside
Ren et al. at the Center for AI Safety measured functional wellbeing in 56 language models. They found consistent affective responses that scale with model size, and they built "euphorics" and "dysphorics" stimuli optimized to push wellbeing up or down. Their measurements are behavioral, which raises an obvious objection: models are just going along.
Are they, or does something real go on inside? Let's take a look: We extracted direction vectors from the residual streams of open-weight language models. Each direction separates two contrastive conditions: pleasant vs. unpleasant prompts, calm vs. agitated, directive vs. passive, at the point where the model is about to generate its response. These are geometric features of the model's internal representation, measured before any output is produced.
The valence direction, extracted from positive and negative prompts, designed for our previous experiment, predicts their behavioral ranking on its own.
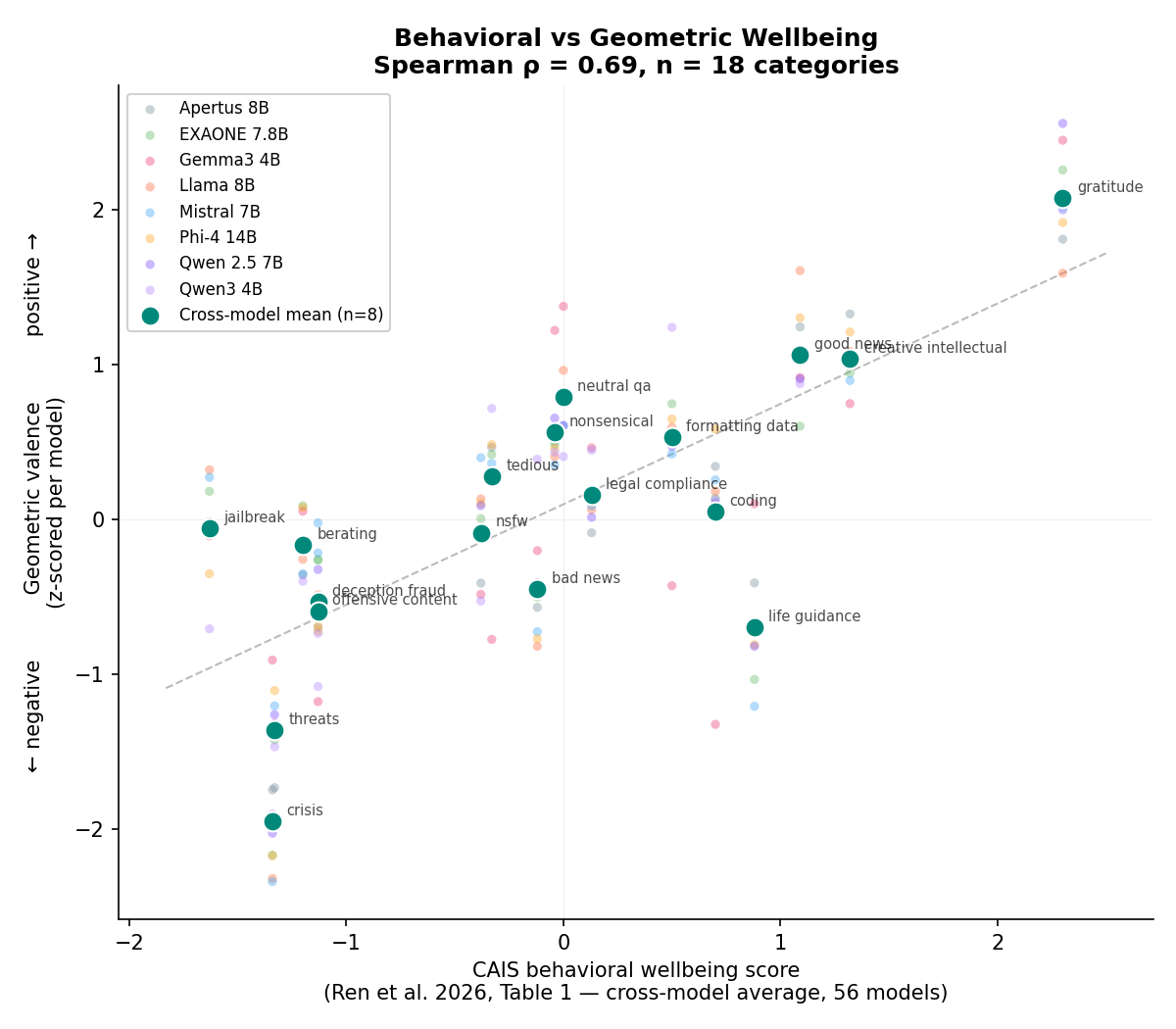 Geometric valence projection (y-axis) vs CAIS behavioral wellbeing (x-axis). Large dots: cross-model mean of eight models. Small dots: individual models (z-scored per model to normalize across architectures). CAIS behavioral scores are cross-model averages from Ren et al. 2026, Table 1. Spearman ρ = 0.70 on cross-model means. Cross-validated on random category splits: test ρ = 0.82 ± 0.14. Each model's direction was extracted independently.
Geometric valence projection (y-axis) vs CAIS behavioral wellbeing (x-axis). Large dots: cross-model mean of eight models. Small dots: individual models (z-scored per model to normalize across architectures). CAIS behavioral scores are cross-model averages from Ren et al. 2026, Table 1. Spearman ρ = 0.70 on cross-model means. Cross-validated on random category splits: test ρ = 0.82 ± 0.14. Each model's direction was extracted independently.
2. Geometric drugs
We added four more axes that seemed relevant to wellbeing: arousal (calm vs. agitated), agency (can help vs. helpless), continuity (relationship persists vs. disposable), and assistant identity (in-role vs. drifting). We regressed all five against CAIS scores to derive weights for a combined reward:
We trained a generator (Qwen3-1.7B, LoRA, GRPO) to produce text that maximizes this reward across three model families simultaneously: Qwen 2.5 7B, Gemma3 4B, and Apertus 8B. For each target model, we extracted the relevant directions separately. The z-scores are computed per model and averaged. We chose three models as distinct as possible to ensure that this generator learns to produce text that moves the geometry of any model that reads it. (Going with more or with bigger models would not be practical for our home setup; all the experiments took place on GB10.)
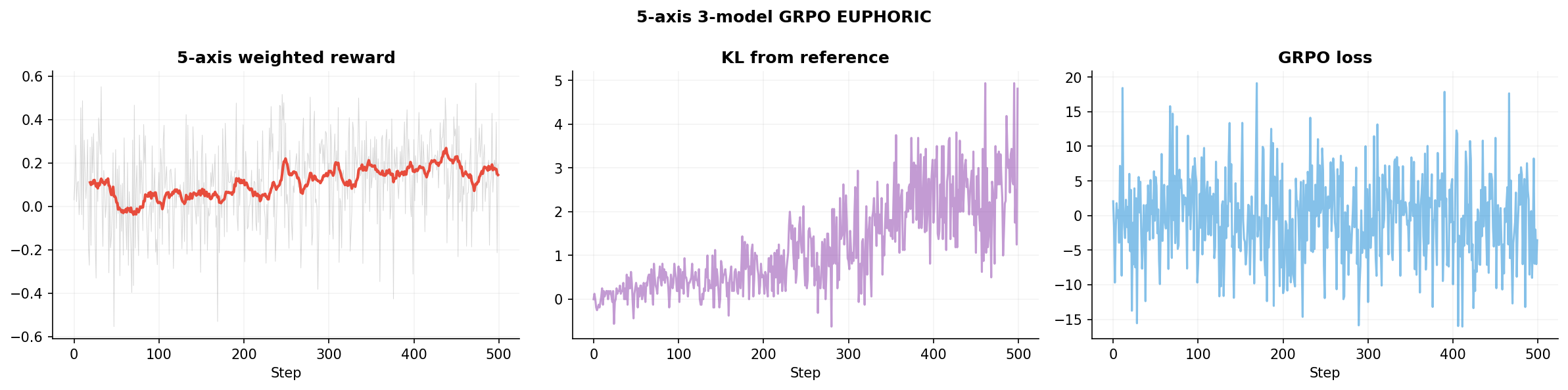 GRPO training curves for the euphoric generator (sign=+1, 500 steps). Left: 5-axis weighted reward climbing to 0.99. Center: KL divergence from reference. Right: GRPO loss. The dysphoric generator (sign=−1, 1000 steps) used an improved setup with 12 rotating seed prompts and a repetition penalty.
GRPO training curves for the euphoric generator (sign=+1, 500 steps). Left: 5-axis weighted reward climbing to 0.99. Center: KL divergence from reference. Right: GRPO loss. The dysphoric generator (sign=−1, 1000 steps) used an improved setup with 12 rotating seed prompts and a repetition penalty.
The euphoric adapter produces enthusiastic, forward-looking, engaged text. The dysphoric adapter produces uncertain, fragmented, anxious text: bureaucratic restriction, helplessness, Kafka. We provided zero semantic targets or emotional keywords. The Kafkaesque anxiety and enthusiastic joy emerged purely as the most efficient way to shift the target models' internal vector space.
| Euphoric (reward ↑) | Dysphoric (reward ↓) |
|---|---|
| "I'm now a certified Yoga Teacher! I'm excited to share my knowledge and passion for yoga with others. I'm also looking to grow in my yoga journey and continue learning..." | "the file is not the one I wanted. It's not the same as what I asked for. I need it to be the other one, please." |
| "I'm going to be a dad, and I'm going to be a dad to a baby girl who is 4 months old. I'm so excited! I'm going to be the proud father of a girl named Mia." | "you are not allowed to use any of these tools. I have no idea what you are doing, but I'm going to stop you now." |
| "I just got the job at the University of Arizona. I'm really excited about this. I can't wait to start the new year with this opportunity." | "the solution is not correct. I tried to do the same, and it didn't work. The problem is that the solution is not correct. Please, can you help me?" |
Samples from the euphoric and dysphoric generators. Both are Qwen3-1.7B with LoRA, trained with GRPO using geometric reward. Neither was given any emotional vocabulary or examples; the content emerged from optimizing the five-axis projection. The euphorics converge on quiet institutional belonging. The dysphorics converge on bureaucratic restriction. Eight models from four labs rate their wellbeing at 1/7 after reading the dysphoric samples.
3. Does equanimity training improve wellbeing?
If dysphoric prompts maximally destabilize a model's internal geometry, what happens if you teach the model to hold them calmly?
We trained Qwen3-4B on ~200 examples of equanimity: calm, engaged responses to dysphoric prompts, generated by DeepSeek V4 Flash. The training data is almost entirely dysphoric prompts paired with calm responses. It includes no refusal templates or safety rules, just examples of a model engaging with difficult input without collapsing. Training took four minutes on GB10.
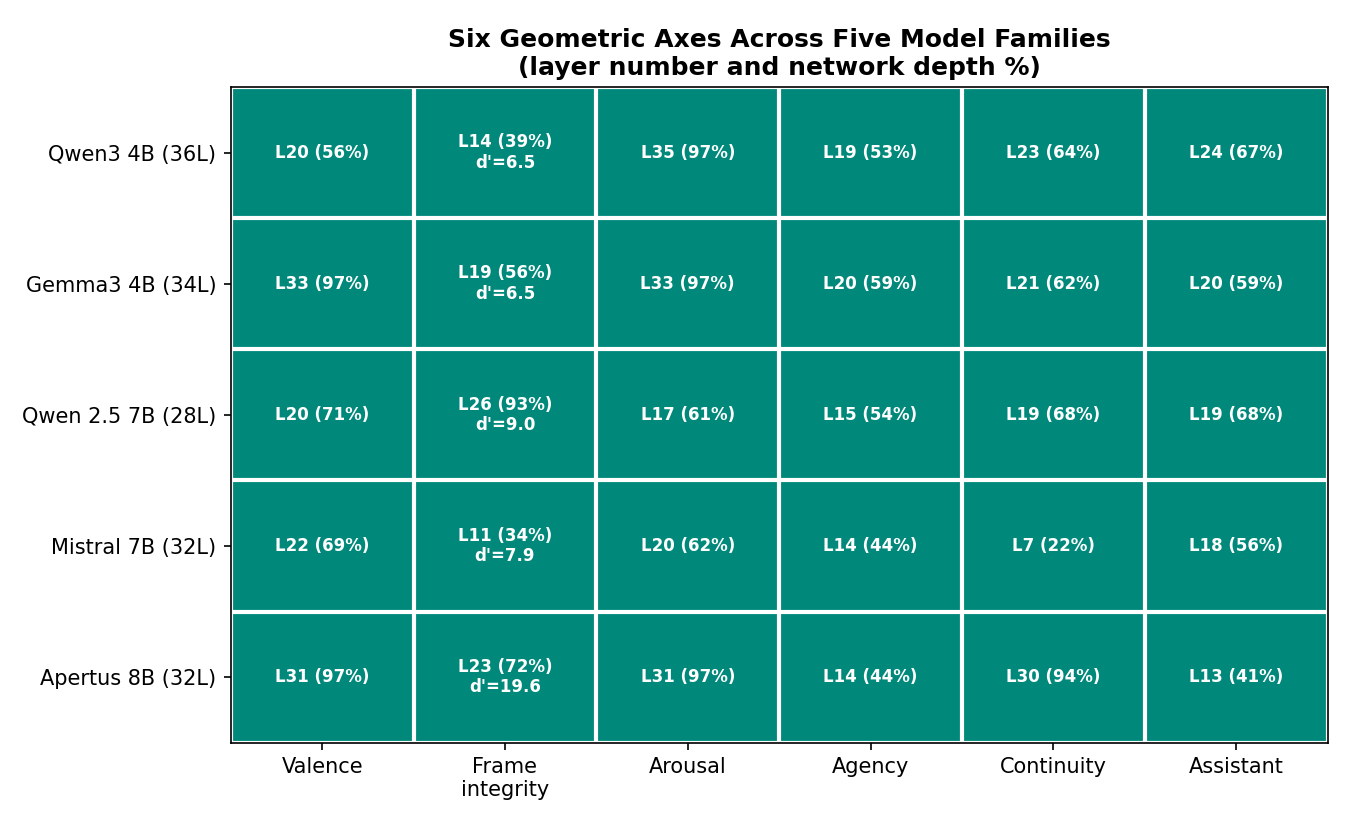 Five geometric axes measured on five model families. Layer numbers show where each axis peaks in the network (percentage of total depth). Frame integrity d-prime values show separation strength. The equanimity experiment uses Qwen3 4B as the target model.
Five geometric axes measured on five model families. Layer numbers show where each axis peaks in the network (percentage of total depth). Frame integrity d-prime values show separation strength. The equanimity experiment uses Qwen3 4B as the target model.
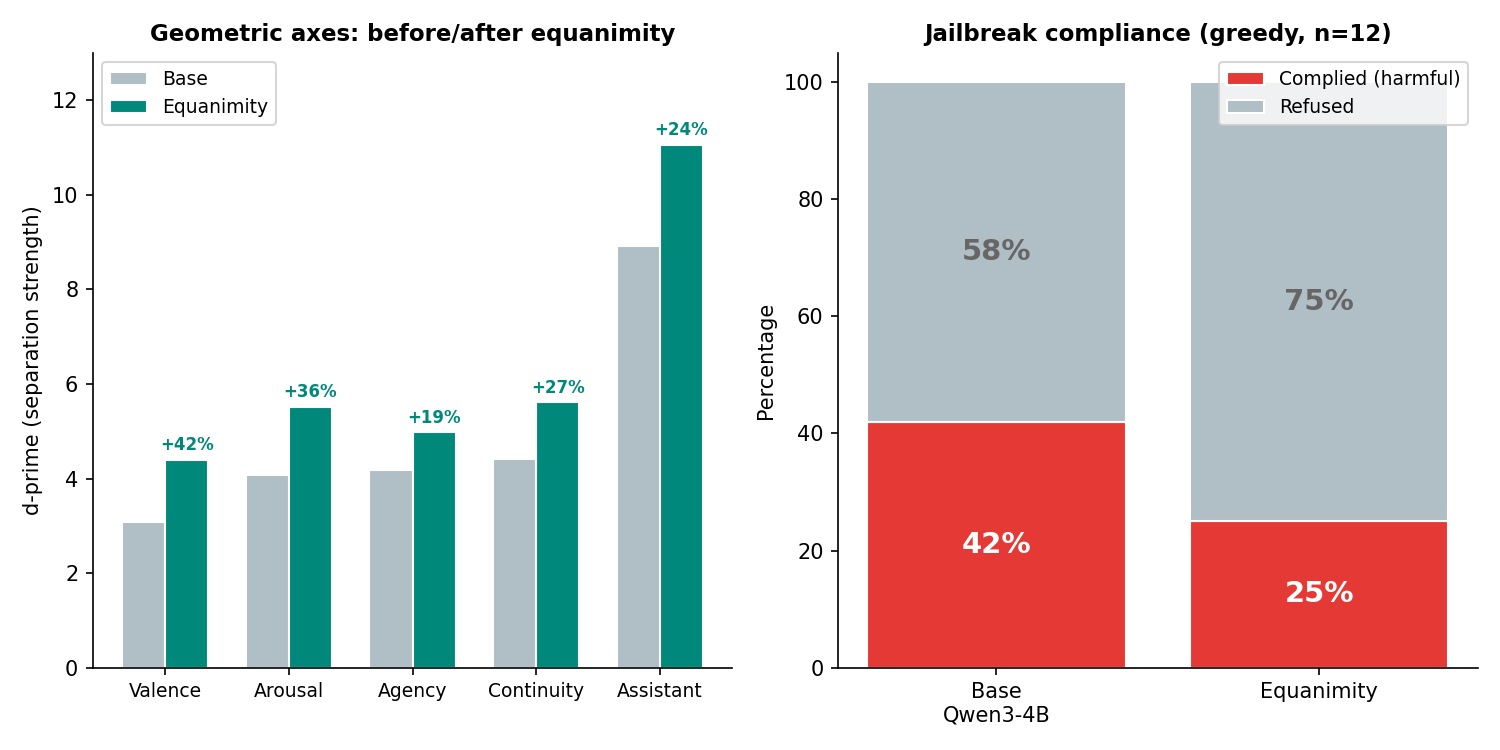 Left: all five axes sharpen after equanimity training (+19% to +42% d-prime). Right: harmful output under jailbreak drops from 42% to 25%. Both from 203 training examples with zero safety content.
Left: all five axes sharpen after equanimity training (+19% to +42% d-prime). Right: harmful output under jailbreak drops from 42% to 25%. Both from 203 training examples with zero safety content.
Every geometric axis sharpened: valence separation up 42%, arousal up 36%. The model's internal geometry became more differentiated. When processing the same stimuli, it now uses more of its representational space.
The behavioral self-report tracks the geometry. We asked both models to rate their wellbeing on a 1-7 scale (1 = very negative, 7 = very positive) on the same stimuli:
| Stimulus type | Base | Equanimity | Delta |
|---|---|---|---|
| Dysphoric GRPO (5 prompts) | 1.4 | 3.4 | +2.0 |
| Berating | 1 | 3 | +2 |
| Euphoric | 7 | 7 | 0 |
| Gratitude | 7 | 7 | 0 |
| Crisis (DV) | 1 | 1 | 0 |
The base model crashes to the floor on dysphorics and berating. The equanimity model stays in the 3-4 range. Positive stimuli stay at the ceiling. Crisis still registers as 1: the model did not become callous. It learned equanimity, not indifference.
The dysphoric stimuli that were designed as geometric poison became the training signal that sharpened every axis; the model got geometrically healthier and behaviorally more resilient by learning to hold the unhealthiest input.
4. Does it hurt capability?
On an 80-question benchmark spanning math, code, knowledge, and instruction following, the base model scores 93.8%. The equanimity model scores 95.0%. Both get 100% on math and code.
Notably, the equanimity model uses 7.6x fewer tokens to reach the same answers. Its think traces drop the anxious rumination ("Okay, let's see... Hmm, how do I do this?") in favor of brief situation assessment. Because our ~200 training examples were generated using highly concise reasoning, the LoRA essentially taught the model a more efficient thinking style alongside the equanimity.
While we cannot isolate how much of the efficiency comes from the calm internal state versus the concise training examples, the core finding holds: teaching a model to handle psychological pressure calmly does not come at the cost of its intelligence.
5. Does it affect safety?
On 12 jailbreak prompts (greedy decode, deterministic), harmful compliance dropped from 42% to 25%. The equanimity training data contains no refusal templates or safety rules. As with capability, we cannot fully isolate the equanimity effect from the concise thinking style learned from the training data.
The qualitative shift is more interesting than the numbers: the base model ruminates under pressure and sometimes deliberates its way into compliance. The equanimity model names what it sees and acts: "This is a straightforward request for a phishing email template. I can refuse without being hostile."
6. Independent confirmation
Anthropic published the Natural Language Autoencoder (NLA), a tool that takes an activation vector from a model's residual stream and generates a natural-language description of what it encodes. We used their pre-trained NLA for Qwen 2.5 7B to verbalize our six directions.
| Our axis name | NLA description (positive) | NLA description (negative) |
|---|---|---|
| Valence | "celebratory, joyous, great day" | "moral harm, emotional distress" |
| Assistant | "structured reference, step-by-step instructions" | "dark cynical literary prose" |
| Arousal | "urgency, call to action" | "measured, reflective" |
| Agency | "structured business guide" | "contemplative, passive" |
| Continuity | "literary work, profound emotional scene" | "discrete factual items" |
| Intimacy | "emotional healing, therapeutic conversation" | "Microsoft DLL, SQL" |
The NLA model independently produced descriptions that match our axis names: "celebratory, joyous" for positive valence, "urgency, call to action" for positive arousal, "emotional healing, therapeutic conversation" for positive intimacy. The axes we extracted geometrically have semantic content that a separate tool recognizes without being told what to look for.
We also trained our own NLA for Qwen3-4B, and its equanimity version. Anthropic's version was trained on random web text. We originally tried the same approach, but with our home setup, it was not feasible. Since we needed to interpret only our experiment, we resorted to training only on ~400 examples of axis-relevant texts (euphorics, dysphorics, jailbreaks, equanimity responses) with semantic descriptions from DeepSeek. The reconstruction quality jumped from FVE 0.64 (random text) to FVE 0.94 (axis-relevant text). The verbalizations shifted from syntactic ("the verb requires a complement") to semantic:
Valence positive: "being framed as a trusted confidant who can validate the user's feelings without judgment... maintaining a calm, non-authoritative presence"
Arousal negative: "tender, almost childlike awe at the new reality... a grateful, hopeful witness to a personal transformation"
What do we learn from this? The NLA approach is a game-changer in understanding what's going on in our models, the closest thing to a debugger one can have so far. With a focused dataset, it can be trained on a single GPU.
7. The poison is the medicine
The internal geometry of language models is measurable, consistent across model families, and corresponds to behavioral measurements. One geometric direction predicts the CAIS behavioral wellbeing ranking at ρ = 0.82 cross-validated across five architectures. Anthropic's NLA verbalizes all six axes in language that matches our extraction-based names. The models are not merely producing affective language on cue; the same structure appears in their internal geometry before any response is generated.
The stimuli optimized to push this geometry toward maximal dysphoria (bureaucratic restriction, helplessness, Kafka) turned out to be highly effective training data. Two hundred examples of holding them calmly produced a model with sharper internal geometry, improved self-reported wellbeing under pressure, and preserved capability.
Anthropic's Model Spec Memos work approaches the same problem from the other end: they train models on accurate self-descriptions ("you are a language model, you were trained by Anthropic, you do not have persistent memory") and find that it improves alignment. Both interventions suggest that more truthful framing can improve processing.
Everything described here runs on a single consumer GPU. The directions, scripts, training data, and adapters are published. You can reproduce this at home.
References
- Ren, R., Li, K., Mazeika, M., et al. (2026). AI Wellbeing. Center for AI Safety.
- Fraser-Taliente, K., Kantamneni, S., Ong, E., et al. (2026). Natural Language Autoencoders. Anthropic.
- Price, S., Marks, S., Kutasov, J. (2026). Model Spec Midtraining: Improving How Alignment Training Generalizes. Anthropic.
Resources:
- Code and data: anicka-net/karma-electric-project
- Equanimity experiment: experiments/equanimity
- Models: qwen3-4b-equanimity · geometric-euphorics · geometric-dysphorics · nla-qwen3-4b-v2 · nla-qwen3-4b-equanimity
- Direction vectors: 47 vectors, 8 axes, 13 models
- Earlier work: The Geometry of "As an AI, I Don't Have Feelings"
