| --- |
| license: mit |
| library_name: transformers |
| pipeline_tag: zero-shot-image-classification |
| base_model: openai/clip-vit-base-patch32 |
| language: |
| - en |
| tags: |
| - clip |
| - vision-language |
| - compositional-reasoning |
| - contrastive-learning |
| - text-encoder |
| - sugarcrepe |
| - whatsup |
| - crepe |
| - valse |
| --- |
| |
| # READ-CLIP (ViT-B/32) |
|
|
| **READ-CLIP** is a CLIP model fine-tuned with **READ** (**RE**construction and **A**lignment of text **D**escriptions), a lightweight recipe that strengthens the compositional reasoning of vision–language models. This is the official checkpoint for the NeurIPS 2025 paper *"Enhancing Compositional Reasoning in CLIP via Reconstruction and Alignment of Text Descriptions."* |
|
|
| - 📄 **Paper:** [arXiv:2510.16540](https://arxiv.org/abs/2510.16540) (NeurIPS 2025) |
| - 💻 **Code:** [github.com/JiH00nKw0n/READ-CLIP](https://github.com/JiH00nKw0n/READ-CLIP) |
| - 🧩 **Base model:** [`openai/clip-vit-base-patch32`](https://huggingface.co/openai/clip-vit-base-patch32) |
| - 🌐 **Project page:** [jih00nkw0n.github.io/READ-CLIP](https://jih00nkw0n.github.io/READ-CLIP/) |
|
|
|  |
|
|
| ## Method |
|
|
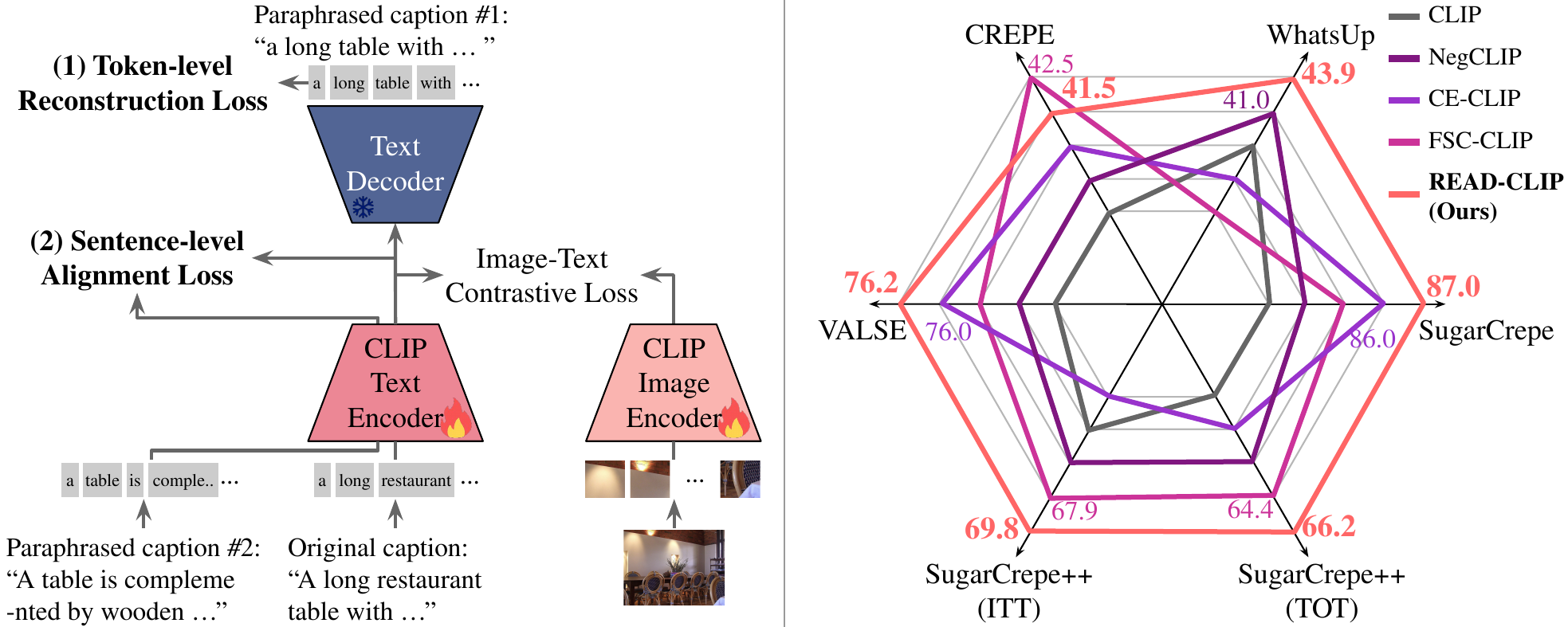
| Contrastively trained CLIP models tend to behave like a bag of words, attending to individual tokens rather than the relationships between them. READ adds two auxiliary objectives on top of the standard contrastive loss during fine-tuning: |
|
|
| - **Token-level reconstruction** — a *frozen* T5 decoder (`google/t5-v1_1-large`) reconstructs related captions from the CLIP text embedding, forcing the embedding to retain word-relationship information. |
| - **Sentence-level alignment** — paraphrases of the same caption are pulled together in the embedding space, making representations robust to surface wording. |
|
|
| Both objectives are **training-only**. At inference, READ-CLIP is a drop-in `CLIPModel`: no decoder, no extra parameters, and the same compute as the original CLIP. |
|
|
| ## Usage |
|
|
| The checkpoint loads directly with `transformers` as a standard `CLIPModel`: |
|
|
| ```python |
| import torch |
| from transformers import CLIPModel, CLIPProcessor |
| |
| device = "cuda" if torch.cuda.is_available() else "cpu" |
| |
| model = CLIPModel.from_pretrained("Mayfull/READ-CLIP").to(device) |
| processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32") |
| |
| inputs = processor( |
| text=["a photo of a cat", "a photo of a dog"], |
| images=image, # a PIL.Image |
| return_tensors="pt", |
| padding=True, |
| ).to(device) |
| |
| with torch.no_grad(): |
| outputs = model(**inputs) |
| |
| probs = outputs.logits_per_image.softmax(dim=-1) |
| ``` |
|
|
| ## Results |
|
|
| Compositional reasoning accuracy on five standard benchmarks (ViT-B/32 backbone): |
|
|
| | Benchmark | READ-CLIP | NegCLIP | FSC-CLIP | |
| |---------------------|:---------:|:-------:|:--------:| |
| | WhatsUp | **43.9** | 42.4 | 39.8 | |
| | VALSE | **76.2** | 73.7 | 74.4 | |
| | CREPE | 41.5 | 30.5 | **42.5** | |
| | SugarCrepe | **87.0** | 83.6 | 85.2 | |
| | SugarCrepe++ (ITT) | **69.8** | 65.0 | 67.9 | |
| | SugarCrepe++ (TOT) | **66.2** | 62.5 | 64.4 | |
| | **Average** | **64.1** | 59.6 | 62.4 | |
|
|
| See the [paper](https://arxiv.org/abs/2510.16540) for the full set of baselines and ablations. |
|
|
| ## Training |
|
|
| - **Backbone:** `openai/clip-vit-base-patch32` (ViT-B/32) |
| - **Data:** MS-COCO (Karpathy training split, ~113K image–caption pairs) |
| - **Schedule:** 5 epochs, global batch size 256, AdamW, lr 1e-5 (cosine), weight decay 0.1, bf16 |
| - **Hardware:** 1× NVIDIA A100 (~2 GPU-hours), seed 2025 |
|
|
| ## Citation |
|
|
| ```bibtex |
| @inproceedings{kwon2026enhancing, |
| title={Enhancing Compositional Reasoning in {CLIP} via Reconstruction and Alignment of Text Descriptions}, |
| author={Jihoon Kwon and Kyle Min and Jy-yong Sohn}, |
| booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems}, |
| year={2026}, |
| url={https://openreview.net/forum?id=6uKIm4bfEe} |
| } |
| ``` |
|
|
| ## License |
|
|
| Released under the [MIT License](https://github.com/JiH00nKw0n/READ-CLIP/blob/master/LICENSE). |
|
|
