

license: apache-2.0
datasets:
- TIGER-Lab/WebInstruct-verified
base_model:
- Qwen/Qwen3-14B-Base
pipeline_tag: question-answering
General-Reasoner: Advancing LLM Reasoning Across All Domains
💻 Code | 📄 Paper | 📊 Dataset | 🤗 Model | 🌐 Project Page
Overview
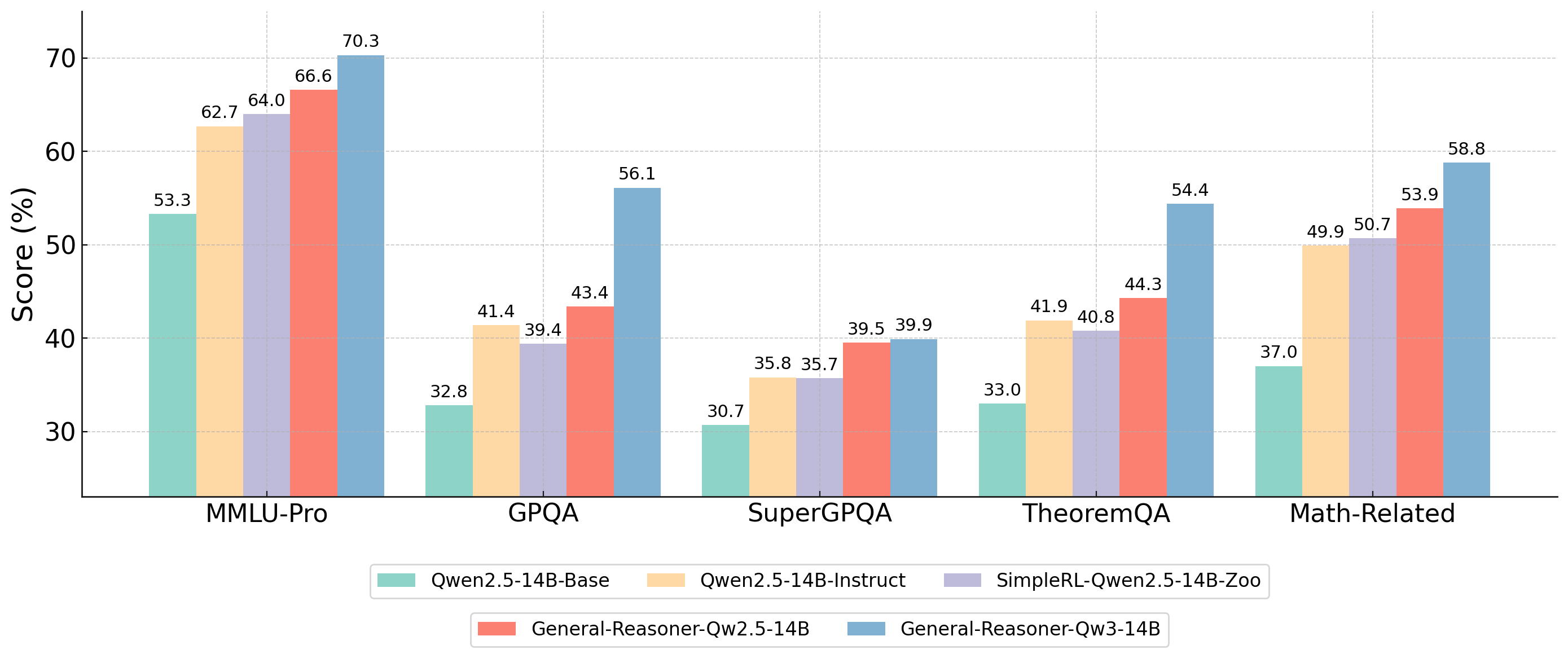
Figure: Effectiveness of General-Reasoner trained with diverse verifiable reasoning questions using model-based verifier compared to baseline methods on various reasoning tasks.
General-Reasoner is a training paradigm for large language models (LLMs), designed to robustly enhance reasoning abilities across diverse domains—not just mathematics and coding, but also physics, chemistry, finance, humanities, and more.
Key features:
- Zero RL Training: Direct reinforcement learning from base LLMs, bypassing intermediate supervised stages.
- Diverse Reasoning Data: 230K+ high-quality, verifiable questions sourced from the web and filtered for answer verifiability across disciplines.
- Model-Based Verifier: Compact 1.5B generative verifier model for context-aware, chain-of-thought answer validation, outperforming traditional rule-based methods.
This specific model is the General-Reasoner variant trained based on Qwen3-14B-Base.
Main Results
General-Reasoner outperforms base and supervised models on a variety of reasoning benchmarks, demonstrating robust generalization across domains:

Citation
If you feel our work is helpful, please cite:
@article{general-reasoner,
title={{G}eneral-{R}easoner: Advancing LLM Reasoning Across All Domains},
author={Xueguang Ma and Qian Liu and Dongfu Jiang and Ge Zhang and Zejun Ma and Wenhu Chen},
year={2025},
journal={arXiv:2505.14652},
url={https://arxiv.org/abs/2505.14652}
}