
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 1.62B | node_id stringlengths 18 32 | number int64 1 5.62k | title stringlengths 1 290 | user dict | labels list | state stringclasses 1
value | locked bool 1
class | assignee dict | assignees list | milestone dict | comments list | created_at timestamp[s] | updated_at timestamp[s] | closed_at timestamp[s] | author_association stringclasses 3
values | active_lock_reason null | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 2
values | draft bool 2
classes | pull_request dict | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5183 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5183/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5183/comments | https://api.github.com/repos/huggingface/datasets/issues/5183/events | https://github.com/huggingface/datasets/issues/5183 | 1,431,418,066 | I_kwDODunzps5VUbTS | 5,183 | Loading an external dataset in a format similar to conll2003 | {
"login": "Taghreed7878",
"id": 112555442,
"node_id": "U_kgDOBrV1sg",
"avatar_url": "https://avatars.githubusercontent.com/u/112555442?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Taghreed7878",
"html_url": "https://github.com/Taghreed7878",
"followers_url": "https://api.github.com/users/Taghreed7878/followers",
"following_url": "https://api.github.com/users/Taghreed7878/following{/other_user}",
"gists_url": "https://api.github.com/users/Taghreed7878/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Taghreed7878/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Taghreed7878/subscriptions",
"organizations_url": "https://api.github.com/users/Taghreed7878/orgs",
"repos_url": "https://api.github.com/users/Taghreed7878/repos",
"events_url": "https://api.github.com/users/Taghreed7878/events{/privacy}",
"received_events_url": "https://api.github.com/users/Taghreed7878/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-11-01T13:18:29 | 2022-11-02T11:57:50 | 2022-11-02T11:57:50 | NONE | null | I'm trying to load a custom dataset in a Dataset object, it's similar to conll2003 but with 2 columns only (word entity), I used the following script:
features = datasets.Features(
{"tokens": datasets.Sequence(datasets.Value("string")),
"ner_tags": datasets.Sequence(
datasets.features.ClassLabel(
names=["B-PER", .... etc.]))}
)
from datasets import Dataset
INPUT_COLUMNS = "tokens ner_tags".split(" ")
def read_conll(file):
#all_labels = []
example = {col: [] for col in INPUT_COLUMNS}
idx = 0
with open(file) as f:
for line in f:
if line:
if line.startswith("-DOCSTART-") and example["tokens"] != []:
print(idx, example)
yield idx, example
idx += 1
example = {col: [] for col in INPUT_COLUMNS}
elif line == "\n" or (line.startswith("-DOCSTART-") and example["tokens"] == []):
continue
else:
row_cols = line.split(" ")
for i, col in enumerate(example):
example[col] = row_cols[i].rstrip()
dset = Dataset.from_generator(read_conll, gen_kwargs={"file": "/content/new_train.txt"}, features = features)
The following error happened:
[/usr/local/lib/python3.7/dist-packages/datasets/utils/py_utils.py](https://localhost:8080/#) in <genexpr>(.0)
285 for key in unique_values(itertools.chain(*dicts)): # set merge all keys
286 # Will raise KeyError if the dict don't have the same keys
--> 287 yield key, tuple(d[key] for d in dicts)
288
TypeError: tuple indices must be integers or slices, not str
What does this mean and what should I modify? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5183/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5183/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5182 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5182/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5182/comments | https://api.github.com/repos/huggingface/datasets/issues/5182/events | https://github.com/huggingface/datasets/issues/5182 | 1,431,029,547 | I_kwDODunzps5VS8cr | 5,182 | Add notebook / other resource links to the task-specific data loading guides | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://a... | null | [
"Yea this would be great! We would need an object detection tutorial notebook too if it doesn't already exist there. ",
"There is one: https://huggingface.co/docs/datasets/object_detection.\r\n\r\nI will start the work. "
] | 2022-11-01T07:57:26 | 2022-11-03T01:49:57 | 2022-11-03T01:49:57 | MEMBER | null | Does it make sense to include links to notebooks / scripts that show how to use a dataset for training / fine-tuning a model?
For example, here in [https://huggingface.co/docs/datasets/image_classification] we could include a mention of https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb.
Applies to https://huggingface.co/docs/datasets/object_detection as well.
Cc: @osanseviero @nateraw | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5182/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5182/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5181 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5181/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5181/comments | https://api.github.com/repos/huggingface/datasets/issues/5181/events | https://github.com/huggingface/datasets/issues/5181 | 1,431,027,102 | I_kwDODunzps5VS72e | 5,181 | Add a guide for semantic segmentation | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | closed | false | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://a... | null | [
"Sure this sounds great! Would this be pure torchvision, albumentations, or something else?",
"I am considering `torchvision` and `albumentations`. Also [works with TensorFlow](https://github.com/deep-diver/segformer-tf-transformers/blob/main/notebooks/TFSegFormer_Finetune.ipynb). \r\n\r\nI am assigning the issue... | 2022-11-01T07:54:50 | 2022-11-04T18:23:36 | 2022-11-04T18:23:36 | MEMBER | null | Currently, we have these guides for object detection and image classification:
* https://huggingface.co/docs/datasets/object_detection
* https://huggingface.co/docs/datasets/image_classification
I am proposing adding a similar guide for semantic segmentation.
I am happy to contribute a PR for it.
Cc: @osanseviero @nateraw | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5181/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5181/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5179 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5179/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5179/comments | https://api.github.com/repos/huggingface/datasets/issues/5179/events | https://github.com/huggingface/datasets/issues/5179 | 1,430,826,100 | I_kwDODunzps5VSKx0 | 5,179 | `map()` fails midway due to format incompatibility | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "https://api.github.com/users/sayakpaul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sayakpaul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sayakpaul/subscriptions",
"organizations_url": "https://api.github.com/users/sayakpaul/orgs",
"repos_url": "https://api.github.com/users/sayakpaul/repos",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"received_events_url": "https://api.github.com/users/sayakpaul/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Cc: @lhoestq ",
"You can end up with a list instead of a tensor if all the tensors inside the list can't be stacked together - can you make sure all your inputs are tensors with the same shape ?",
"Is there an easy way to ensure it?",
"You can make sure your `tokenize` function always return tensors of the s... | 2022-11-01T03:57:59 | 2022-11-08T11:35:26 | 2022-11-08T11:35:26 | MEMBER | null | ### Describe the bug
I am using the `emotion` dataset from Hub for sequence classification. After training the model, I am using it to generate predictions for all the entries present in the `validation` split of the dataset.
```py
def get_test_accuracy(model):
def fn(batch):
inputs = {k:v.to(device) for k,v in batch.items()
if k in tokenizer.model_input_names}
with torch.no_grad():
output = model(**inputs)
pred_label = torch.argmax(output.logits, axis=-1)
return {"predicted_label": pred_label.cpu().numpy()}
return fn
```
This is how the `get_test_accuracy()` is being used:
```py
emotions = load_dataset("emotion")
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)
emotions_encoded = emotions.map(tokenize, batched=True)
emotions_encoded.set_format("torch",
columns=["input_ids", "attention_mask", "label"])
new_dataset = emotions_encoded["validation"].map(
accuracy_fn, batched=True, batch_size=128
)
```
Complete code is available in the Colab Notebook provided below.
The `map()` process fails midway giving:
```shell
AttributeError Traceback (most recent call last)
<ipython-input-8-ad24ac288eb4> in <module>
2
3 new_dataset = emotions_encoded["validation"].map(
----> 4 accuracy_fn, batched=True, batch_size=128
5 )
7 frames
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in map(self, function, with_indices, with_rank, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint, desc)
2588 new_fingerprint=new_fingerprint,
2589 disable_tqdm=disable_tqdm,
-> 2590 desc=desc,
2591 )
2592 else:
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
582 self: "Dataset" = kwargs.pop("self")
583 # apply actual function
--> 584 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
585 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
586 for dataset in datasets:
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
549 }
550 # apply actual function
--> 551 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
552 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
553 # re-apply format to the output
/usr/local/lib/python3.7/dist-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
478 # Call actual function
479
--> 480 out = func(self, *args, **kwargs)
481
482 # Update fingerprint of in-place transforms + update in-place history of transforms
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in _map_single(self, function, with_indices, with_rank, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset, disable_tqdm, desc, cache_only)
2970 indices,
2971 check_same_num_examples=len(input_dataset.list_indexes()) > 0,
-> 2972 offset=offset,
2973 )
2974 except NumExamplesMismatchError:
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in apply_function_on_filtered_inputs(inputs, indices, check_same_num_examples, offset)
2850 if with_rank:
2851 additional_args += (rank,)
-> 2852 processed_inputs = function(*fn_args, *additional_args, **fn_kwargs)
2853 if update_data is None:
2854 # Check if the function returns updated examples
<ipython-input-6-4e0d280426f6> in fn(batch)
1 def get_test_accuracy(model):
2 def fn(batch):
----> 3 inputs = {k:v.to(device) for k,v in batch.items()
4 if k in tokenizer.model_input_names}
5 with torch.no_grad():
<ipython-input-6-4e0d280426f6> in <dictcomp>(.0)
2 def fn(batch):
3 inputs = {k:v.to(device) for k,v in batch.items()
----> 4 if k in tokenizer.model_input_names}
5 with torch.no_grad():
6 output = model(**inputs)
AttributeError: 'list' object has no attribute 'to'
```
As you'd notice in the notebook, the process fails _midway_ and not at the beginning.
Is this expected?
### Steps to reproduce the bug
Colab Notebook:
https://colab.research.google.com/gist/sayakpaul/d1570d537faf39040d02d77b1ed7de07/scratchpad.ipynb
### Expected behavior
The mapping process should complete as is. If you switch the `split` to `test` it works as expected.
### Environment info
Colab | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5179/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5179/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5178 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5178/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5178/comments | https://api.github.com/repos/huggingface/datasets/issues/5178/events | https://github.com/huggingface/datasets/issues/5178 | 1,430,800,810 | I_kwDODunzps5VSEmq | 5,178 | Unable to download the Chinese `wikipedia`, the dumpstatus.json not found! | {
"login": "beyondguo",
"id": 37113676,
"node_id": "MDQ6VXNlcjM3MTEzNjc2",
"avatar_url": "https://avatars.githubusercontent.com/u/37113676?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/beyondguo",
"html_url": "https://github.com/beyondguo",
"followers_url": "https://api.github.com/users/beyondguo/followers",
"following_url": "https://api.github.com/users/beyondguo/following{/other_user}",
"gists_url": "https://api.github.com/users/beyondguo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/beyondguo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/beyondguo/subscriptions",
"organizations_url": "https://api.github.com/users/beyondguo/orgs",
"repos_url": "https://api.github.com/users/beyondguo/repos",
"events_url": "https://api.github.com/users/beyondguo/events{/privacy}",
"received_events_url": "https://api.github.com/users/beyondguo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"In the dumps page of the wiki (https://dumps.wikimedia.org/zhwiki/), I found the following dumps:\r\n```\r\nIndex of /zhwiki/\r\n[../](https://dumps.wikimedia.org/)\r\n[20220701/](https://dumps.wikimedia.org/zhwiki/20220701/) 21-Aug-2022 01:48 -\r\n[202207... | 2022-11-01T03:17:55 | 2022-11-02T08:27:15 | 2022-11-02T08:24:29 | NONE | null | ### Describe the bug
I tried:
`data = load_dataset('wikipedia', '20220301.zh', beam_runner='DirectRunner')`
and
`data = load_dataset("wikipedia", language="zh", date="20220301", beam_runner='DirectRunner')`
but both got:
`FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/zhwiki/20220301/dumpstatus.json`
the full report is:
```
FileNotFoundError Traceback (most recent call last)
<ipython-input-13-d07c5021090c> in <module>
1 from datasets import load_dataset
2
----> 3 data = load_dataset("wikipedia", language="zh", date="20220301", beam_runner='DirectRunner')<?, ?it/s]
/opt/conda/lib/python3.8/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1740
1741 # Download and prepare data
-> 1742 builder_instance.download_and_prepare(
1743 download_config=download_config,
1744 download_mode=download_mode,
/opt/conda/lib/python3.8/site-packages/datasets/builder.py in download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, storage_options, **download_and_prepare_kwargs)
812 **download_and_prepare_kwargs,
813 }
--> 814 self._download_and_prepare(
815 dl_manager=dl_manager,
816 verify_infos=verify_infos,
/opt/conda/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_splits_kwargs)
1645 options=beam_options,
1646 )
-> 1647 super()._download_and_prepare(
1648 dl_manager, verify_infos=False, pipeline=pipeline, **prepare_splits_kwargs
1649 ) # TODO handle verify_infos in beam datasets
/opt/conda/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
881 split_dict = SplitDict(dataset_name=self.name)
882 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 883 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
884
885 # Checksums verification
~/.cache/huggingface/modules/datasets_modules/datasets/wikipedia/aa542ed919df55cc5d3347f42dd4521d05ca68751f50dbc32bae2a7f1e167559/wikipedia.py in _split_generators(self, dl_manager, pipeline)
943 info_url = _base_url(lang) + _INFO_FILE
944 # Use dictionary since testing mock always returns the same result.
--> 945 downloaded_files = dl_manager.download_and_extract({"info": info_url})
946
947 xml_urls = []
/opt/conda/lib/python3.8/site-packages/datasets/download/download_manager.py in download_and_extract(self, url_or_urls)
431 extracted_path(s): `str`, extracted paths of given URL(s).
432 """
--> 433 return self.extract(self.download(url_or_urls))
434
435 def get_recorded_sizes_checksums(self):
/opt/conda/lib/python3.8/site-packages/datasets/download/download_manager.py in download(self, url_or_urls)
308
309 start_time = datetime.now()
--> 310 downloaded_path_or_paths = map_nested(
311 download_func,
312 url_or_urls,
/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py in map_nested(function, data_struct, dict_only, map_list, map_tuple, map_numpy, num_proc, parallel_min_length, types, disable_tqdm, desc)
427 num_proc = 1
428 if num_proc <= 1 or len(iterable) < parallel_min_length:
--> 429 mapped = [
430 _single_map_nested((function, obj, types, None, True, None))
431 for obj in logging.tqdm(iterable, disable=disable_tqdm, desc=desc)
/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py in <listcomp>(.0)
428 if num_proc <= 1 or len(iterable) < parallel_min_length:
429 mapped = [
--> 430 _single_map_nested((function, obj, types, None, True, None))
431 for obj in logging.tqdm(iterable, disable=disable_tqdm, desc=desc)
432 ]
/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py in _single_map_nested(args)
329 # Singleton first to spare some computation
330 if not isinstance(data_struct, dict) and not isinstance(data_struct, types):
--> 331 return function(data_struct)
332
333 # Reduce logging to keep things readable in multiprocessing with tqdm
/opt/conda/lib/python3.8/site-packages/datasets/download/download_manager.py in _download(self, url_or_filename, download_config)
335 # append the relative path to the base_path
336 url_or_filename = url_or_path_join(self._base_path, url_or_filename)
--> 337 return cached_path(url_or_filename, download_config=download_config)
338
339 def iter_archive(self, path_or_buf: Union[str, io.BufferedReader]):
/opt/conda/lib/python3.8/site-packages/datasets/utils/file_utils.py in cached_path(url_or_filename, download_config, **download_kwargs)
186 if is_remote_url(url_or_filename):
187 # URL, so get it from the cache (downloading if necessary)
--> 188 output_path = get_from_cache(
189 url_or_filename,
190 cache_dir=cache_dir,
/opt/conda/lib/python3.8/site-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag, max_retries, use_auth_token, ignore_url_params, download_desc)
533 )
534 elif response is not None and response.status_code == 404:
--> 535 raise FileNotFoundError(f"Couldn't find file at {url}")
536 _raise_if_offline_mode_is_enabled(f"Tried to reach {url}")
537 if head_error is not None:
FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/zhwiki/20220301/dumpstatus.json
```
### Steps to reproduce the bug
`data = load_dataset('wikipedia', '20220301.zh', beam_runner='DirectRunner')`
### Expected behavior
download the data
### Environment info
python3.6
latest datasets/transformers version | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5178/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5178/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5177 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5177/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5177/comments | https://api.github.com/repos/huggingface/datasets/issues/5177/events | https://github.com/huggingface/datasets/pull/5177 | 1,430,238,556 | PR_kwDODunzps5B55iV | 5,177 | Update create image dataset docs | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | closed | false | null | [] | null | [] | 2022-10-31T17:45:56 | 2022-11-02T17:15:22 | 2022-11-02T17:13:02 | MEMBER | null | Based on @osanseviero and community feedback, it wasn't super clear how to upload a dataset to the Hub after creating something like an image captioning dataset. This PR adds a brief section on how to upload the dataset with `push_to_hub`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5177/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5177/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5177",
"html_url": "https://github.com/huggingface/datasets/pull/5177",
"diff_url": "https://github.com/huggingface/datasets/pull/5177.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5177.patch",
"merged_at": "2022-11-02T17:13:02"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5175 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5175/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5175/comments | https://api.github.com/repos/huggingface/datasets/issues/5175/events | https://github.com/huggingface/datasets/issues/5175 | 1,428,696,231 | I_kwDODunzps5VKCyn | 5,175 | Loading an external NER dataset | {
"login": "Taghreed7878",
"id": 112555442,
"node_id": "U_kgDOBrV1sg",
"avatar_url": "https://avatars.githubusercontent.com/u/112555442?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Taghreed7878",
"html_url": "https://github.com/Taghreed7878",
"followers_url": "https://api.github.com/users/Taghreed7878/followers",
"following_url": "https://api.github.com/users/Taghreed7878/following{/other_user}",
"gists_url": "https://api.github.com/users/Taghreed7878/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Taghreed7878/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Taghreed7878/subscriptions",
"organizations_url": "https://api.github.com/users/Taghreed7878/orgs",
"repos_url": "https://api.github.com/users/Taghreed7878/repos",
"events_url": "https://api.github.com/users/Taghreed7878/events{/privacy}",
"received_events_url": "https://api.github.com/users/Taghreed7878/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-30T09:31:55 | 2022-11-01T13:15:49 | 2022-11-01T13:15:49 | NONE | null | I need to use huggingface datasets to load a custom dataset similar to conll2003 but with more entities and each the files contain only two columns: word and ner tag.
I tried this code snnipet that I found here as an answer to a similar issue:
from datasets import Dataset
INPUT_COLUMNS = "ID Text NER".split()
def read_conll(file):
example = {col: [] for col in INPUT_COLUMNS}
idx = 0
with open(file) as f:
for line in f:
if line.startswith("-DOCSTART-") or line == "\n" or not line:
if example[next(iter(example))]:
yield idx, example
idx += 1
example = {col: [] for col in INPUT_COLUMNS}
else:
row_cols = line.split()
for i, col in enumerate(example):
example[col] = row_cols[i].rstrip()
train = Dataset.from_generator(read_conll, gen_kwargs={"file": "some_path"})
But the following error happened:
ValueError: Please pass `features` or at least one example when writing data | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5175/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5175/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5174 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5174/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5174/comments | https://api.github.com/repos/huggingface/datasets/issues/5174/events | https://github.com/huggingface/datasets/pull/5174 | 1,427,216,416 | PR_kwDODunzps5Bv3rh | 5,174 | Preserve None in list type cast in PyArrow 10 | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-28T12:48:30 | 2022-10-28T13:15:33 | 2022-10-28T13:13:18 | CONTRIBUTOR | null | The `ListArray` type in PyArrow 10.0.0 supports the `mask` parameter, which allows us to preserve Nones in nested lists in `cast` instead of replacing them with empty lists.
Fix https://github.com/huggingface/datasets/issues/3676 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5174/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5174/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5174",
"html_url": "https://github.com/huggingface/datasets/pull/5174",
"diff_url": "https://github.com/huggingface/datasets/pull/5174.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5174.patch",
"merged_at": "2022-10-28T13:13:18"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5173 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5173/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5173/comments | https://api.github.com/repos/huggingface/datasets/issues/5173/events | https://github.com/huggingface/datasets/pull/5173 | 1,425,880,441 | PR_kwDODunzps5BreEm | 5,173 | Raise ffmpeg warnings only once | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-27T15:58:33 | 2022-10-28T16:03:05 | 2022-10-28T16:00:51 | CONTRIBUTOR | null | Our warnings looks nice now.
`librosa` warning that was raised at each decoding:
```
/usr/local/lib/python3.7/dist-packages/librosa/core/audio.py:165: UserWarning: PySoundFile failed. Trying audioread instead.
warnings.warn("PySoundFile failed. Trying audioread instead.")
```
is suppressed with `filterwarnings("ignore")` in a context manager. That means the first warning is also ignored (setting `filterwarnings("once")` didn't work!), so I added info that audioread is used for decoding to our message. Hope it's enough.
Tests failed at first because they used to check if the warning was raised at (each) decoding in `librosa` case but now we throw only one warning (at first decoding). I removed this check for warnings, do you think it's fine? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5173/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5173/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5173",
"html_url": "https://github.com/huggingface/datasets/pull/5173",
"diff_url": "https://github.com/huggingface/datasets/pull/5173.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5173.patch",
"merged_at": "2022-10-28T16:00:51"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5171 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5171/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5171/comments | https://api.github.com/repos/huggingface/datasets/issues/5171/events | https://github.com/huggingface/datasets/pull/5171 | 1,425,355,111 | PR_kwDODunzps5BpsXf | 5,171 | Add PB and TB in convert_file_size_to_int | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-27T09:50:31 | 2022-10-27T12:14:27 | 2022-10-27T12:12:30 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5171/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5171/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5171",
"html_url": "https://github.com/huggingface/datasets/pull/5171",
"diff_url": "https://github.com/huggingface/datasets/pull/5171.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5171.patch",
"merged_at": "2022-10-27T12:12:30"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5170 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5170/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5170/comments | https://api.github.com/repos/huggingface/datasets/issues/5170/events | https://github.com/huggingface/datasets/issues/5170 | 1,425,301,835 | I_kwDODunzps5U9GFL | 5,170 | [Caching] Deterministic hashing of torch tensors | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [] | 2022-10-27T09:15:15 | 2022-11-02T17:18:43 | 2022-11-02T17:18:43 | MEMBER | null | Currently this fails
```python
import torch
from datasets.fingerprint import Hasher
t = torch.tensor([1.])
def func(x):
return t + x
hash1 = Hasher.hash(func)
t = torch.tensor([1.])
hash2 = Hasher.hash(func)
assert hash1 == hash2
```
Also as noticed in https://discuss.huggingface.co/t/dataset-cant-cache-models-outputs/24945, using a model in a `map` function doesn't work well with caching. Indeed the `bert-base-uncased` model has a different hash every time you reload it. Supporting torch tensors may also help in this case.
This can be fixed by registering a custom pickling functions for torch tensors - as we did for other objects such as CodeType, FunctionType and Regex in `py_utils.py` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5170/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5170/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5169 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5169/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5169/comments | https://api.github.com/repos/huggingface/datasets/issues/5169/events | https://github.com/huggingface/datasets/pull/5169 | 1,425,075,254 | PR_kwDODunzps5Bow1Q | 5,169 | Add "ipykernel" to list of `co_filename`s to remove | {
"login": "gpucce",
"id": 32967787,
"node_id": "MDQ6VXNlcjMyOTY3Nzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/32967787?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gpucce",
"html_url": "https://github.com/gpucce",
"followers_url": "https://api.github.com/users/gpucce/followers",
"following_url": "https://api.github.com/users/gpucce/following{/other_user}",
"gists_url": "https://api.github.com/users/gpucce/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gpucce/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gpucce/subscriptions",
"organizations_url": "https://api.github.com/users/gpucce/orgs",
"repos_url": "https://api.github.com/users/gpucce/repos",
"events_url": "https://api.github.com/users/gpucce/events{/privacy}",
"received_events_url": "https://api.github.com/users/gpucce/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-27T05:56:17 | 2022-11-02T15:46:00 | 2022-11-02T15:43:20 | CONTRIBUTOR | null | Should resolve #5157 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5169/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5169/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5169",
"html_url": "https://github.com/huggingface/datasets/pull/5169",
"diff_url": "https://github.com/huggingface/datasets/pull/5169.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5169.patch",
"merged_at": "2022-11-02T15:43:20"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5168 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5168/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5168/comments | https://api.github.com/repos/huggingface/datasets/issues/5168/events | https://github.com/huggingface/datasets/pull/5168 | 1,424,368,572 | PR_kwDODunzps5BmYnq | 5,168 | Fix CI require beam | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-26T16:49:33 | 2022-10-27T09:25:19 | 2022-10-27T09:23:26 | MEMBER | null | This PR:
- Fixes the CI `require_beam`: before it was requiring PyTorch instead
```python
def require_beam(test_case):
if not config.TORCH_AVAILABLE:
test_case = unittest.skip("test requires PyTorch")(test_case)
return test_case
```
- Fixes a missing `require_beam` in `test_beam_based_builder_download_and_prepare_as_parquet`
- Refactors `require_beam` to use `pytest` (`skipif`) instead | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5168/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5168/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5168",
"html_url": "https://github.com/huggingface/datasets/pull/5168",
"diff_url": "https://github.com/huggingface/datasets/pull/5168.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5168.patch",
"merged_at": "2022-10-27T09:23:26"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5167 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5167/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5167/comments | https://api.github.com/repos/huggingface/datasets/issues/5167/events | https://github.com/huggingface/datasets/pull/5167 | 1,424,124,477 | PR_kwDODunzps5BljPw | 5,167 | Add ffmpeg4 installation instructions in warnings | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "... | null | [] | 2022-10-26T14:21:14 | 2022-10-27T09:01:12 | 2022-10-27T08:58:58 | CONTRIBUTOR | null | Adds instructions on how to install `ffmpeg=4` on Linux (relevant for Colab users).
Looks pretty ugly because I didn't find a way to check `ffmpeg` version from python (without `subprocess.call()`; `ctypes.util.find_library` doesn't work`), so the warning is raised on each decoding. Any suggestions on how to make it look nice are welcome!
This is how it looks on Colab:

| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5167/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5167/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5167",
"html_url": "https://github.com/huggingface/datasets/pull/5167",
"diff_url": "https://github.com/huggingface/datasets/pull/5167.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5167.patch",
"merged_at": "2022-10-27T08:58:58"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5166 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5166/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5166/comments | https://api.github.com/repos/huggingface/datasets/issues/5166/events | https://github.com/huggingface/datasets/pull/5166 | 1,423,629,582 | PR_kwDODunzps5Bj5IQ | 5,166 | Support dill 0.3.6 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-26T08:24:59 | 2022-10-28T05:41:05 | 2022-10-28T05:38:14 | MEMBER | null | This PR:
- ~~Unpins dill to allow installing dill>=0.3.6~~
- ~~Removes the fix on dill for >=0.3.6 because they implemented a deterministic mode (to be confirmed by @anivegesana)~~
- Pins dill<0.3.7 to allow latest dill 0.3.6
- Implements a fix for dill `save_function` for dill 0.3.6
- Additionally had to implement a fix for dill `save_code` and `_save_regex` for dill 0.3.6
- Fixes the CI so that the latest dill version is tested (besides the minimum 0.3.1.1 required by apache-beam 2.42.0)
Fix #5162. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5166/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5166/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5166",
"html_url": "https://github.com/huggingface/datasets/pull/5166",
"diff_url": "https://github.com/huggingface/datasets/pull/5166.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5166.patch",
"merged_at": "2022-10-28T05:38:14"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5164 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5164/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5164/comments | https://api.github.com/repos/huggingface/datasets/issues/5164/events | https://github.com/huggingface/datasets/pull/5164 | 1,422,813,247 | PR_kwDODunzps5BhL4J | 5,164 | WIP: drop labels in Image and Audio folders by default | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "... | null | [] | 2022-10-25T17:21:49 | 2022-11-16T14:21:16 | 2022-11-02T14:03:02 | CONTRIBUTOR | null | will fix https://github.com/huggingface/datasets/issues/5153 and redundant labels displaying for most of the images datasets on the Hub (which are used just to store files)
TODO: discuss adding `drop_labels` (and `drop_metadata`) params to yaml | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5164/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5164/timeline | null | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5164",
"html_url": "https://github.com/huggingface/datasets/pull/5164",
"diff_url": "https://github.com/huggingface/datasets/pull/5164.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5164.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5163 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5163/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5163/comments | https://api.github.com/repos/huggingface/datasets/issues/5163/events | https://github.com/huggingface/datasets/pull/5163 | 1,422,540,337 | PR_kwDODunzps5BgQxp | 5,163 | Reduce default max `writer_batch_size` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-25T14:14:52 | 2022-10-27T12:19:27 | 2022-10-27T12:16:47 | CONTRIBUTOR | null | Reduce the default writer_batch_size from 10k to 1k examples. Additionally, align the default values of `batch_size` and `writer_batch_size` in `Dataset.cast` with the values from the corresponding docstring. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5163/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5163/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5163",
"html_url": "https://github.com/huggingface/datasets/pull/5163",
"diff_url": "https://github.com/huggingface/datasets/pull/5163.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5163.patch",
"merged_at": "2022-10-27T12:16:47"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5162 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5162/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5162/comments | https://api.github.com/repos/huggingface/datasets/issues/5162/events | https://github.com/huggingface/datasets/issues/5162 | 1,422,461,112 | I_kwDODunzps5UyQi4 | 5,162 | Pip-compile: Could not find a version that matches dill<0.3.6,>=0.3.6 | {
"login": "Rijgersberg",
"id": 8604946,
"node_id": "MDQ6VXNlcjg2MDQ5NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8604946?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rijgersberg",
"html_url": "https://github.com/Rijgersberg",
"followers_url": "https://api.github.com/users/Rijgersberg/followers",
"following_url": "https://api.github.com/users/Rijgersberg/following{/other_user}",
"gists_url": "https://api.github.com/users/Rijgersberg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rijgersberg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rijgersberg/subscriptions",
"organizations_url": "https://api.github.com/users/Rijgersberg/orgs",
"repos_url": "https://api.github.com/users/Rijgersberg/repos",
"events_url": "https://api.github.com/users/Rijgersberg/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rijgersberg/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Thanks for reporting, @Rijgersberg.\r\n\r\nWe were waiting for the release of `dill` 0.3.6, that happened 2 days ago (24 Oct 2022): https://github.com/uqfoundation/dill/releases/tag/dill-0.3.6\r\n- See comment: https://github.com/huggingface/datasets/pull/4397#discussion_r880629543\r\n\r\nAlso `multiprocess` 0.70.... | 2022-10-25T13:23:50 | 2022-11-14T08:25:37 | 2022-10-28T05:38:15 | NONE | null | ### Describe the bug
When using `pip-compile` (part of `pip-tools`) to generate a pinned requirements file that includes `datasets`, a version conflict of `dill` appears.
It is caused by a transitive dependency conflict between `datasets` and `multiprocess`.
### Steps to reproduce the bug
```bash
$ echo "datasets" > requirements.in
$ pip install pip-tools
$ pip-compile requirements.in
Could not find a version that matches dill<0.3.6,>=0.3.6 (from datasets==2.6.1->-r requirements.in (line 1))
Tried: 0.2, 0.2, 0.2.1, 0.2.1, 0.2.2, 0.2.2, 0.2.3, 0.2.3, 0.2.4, 0.2.4, 0.2.5, 0.2.5, 0.2.6, 0.2.7, 0.2.7.1, 0.2.8, 0.2.8.1, 0.2.8.2, 0.2.9, 0.3.0, 0.3.1, 0.3.1.1, 0.3.2, 0.3.3, 0.3.3, 0.3.4, 0.3.4, 0.3.5, 0.3.5, 0.3.5.1, 0.3.5.1, 0.3.6, 0.3.6
Skipped pre-versions: 0.1a1, 0.2a1, 0.2a1, 0.2b1, 0.2b1
There are incompatible versions in the resolved dependencies:
dill<0.3.6 (from datasets==2.6.1->-r requirements.in (line 1))
dill>=0.3.6 (from multiprocess==0.70.14->datasets==2.6.1->-r requirements.in (line 1))
```
### Expected behavior
A correctly generated file `requirements.txt` with pinned dependencies
### Environment info
Tested with versions `2.6.1, 2.6.0, 2.5.2` on Python 3.8 and 3.10 on Ubuntu 20.04LTS and Python 3.10 on MacOS 12.6 (M1). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5162/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5162/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5161 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5161/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5161/comments | https://api.github.com/repos/huggingface/datasets/issues/5161/events | https://github.com/huggingface/datasets/issues/5161 | 1,422,371,748 | I_kwDODunzps5Ux6uk | 5,161 | Dataset can’t cache model’s outputs | {
"login": "jongjyh",
"id": 37979232,
"node_id": "MDQ6VXNlcjM3OTc5MjMy",
"avatar_url": "https://avatars.githubusercontent.com/u/37979232?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jongjyh",
"html_url": "https://github.com/jongjyh",
"followers_url": "https://api.github.com/users/jongjyh/followers",
"following_url": "https://api.github.com/users/jongjyh/following{/other_user}",
"gists_url": "https://api.github.com/users/jongjyh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jongjyh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jongjyh/subscriptions",
"organizations_url": "https://api.github.com/users/jongjyh/orgs",
"repos_url": "https://api.github.com/users/jongjyh/repos",
"events_url": "https://api.github.com/users/jongjyh/events{/privacy}",
"received_events_url": "https://api.github.com/users/jongjyh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Addressed in https://github.com/huggingface/datasets/pull/5191 (torch.Tensor objects now produce deterministic hashes)"
] | 2022-10-25T12:19:00 | 2022-11-03T16:12:52 | 2022-11-03T16:12:51 | NONE | null | ### Describe the bug
Hi,
I try to cache some outputs of teacher model( Knowledge Distillation ) by using map function of Dataset library, while every time I run my code, I still recompute all the sequences. I tested Bert Model like this, I got different hash every single run, so any idea to deal with this?
### Steps to reproduce the bug
1. run below code
2. get different hash
```
from transformers import BertModel
from transformers import AutoTokenizer
import torch
token = ['hello']
model = BertModel.from_pretrained("bert-base-uncased").eval()
tok = AutoTokenizer.from_pretrained("bert-base-uncased")
def abcd():
with torch.no_grad():
out = model(**tok(token,return_tensors='pt'))[0]
# out = tok(token)
return out
from datasets.fingerprint import Hasher
my_func = abcd
print(Hasher.hash(my_func))
print(abcd())
```
### Expected behavior
I wanna cache all the model output
### Environment info
datasets:2.5.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5161/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5161/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5159 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5159/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5159/comments | https://api.github.com/repos/huggingface/datasets/issues/5159/events | https://github.com/huggingface/datasets/pull/5159 | 1,422,172,080 | PR_kwDODunzps5BfBN9 | 5,159 | fsspec lock reset in multiprocessing | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-25T09:41:59 | 2022-11-03T20:51:15 | 2022-11-03T20:48:53 | MEMBER | null | `fsspec` added a clean way of resetting its lock - instead of doing it manually | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5159/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5159/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5159",
"html_url": "https://github.com/huggingface/datasets/pull/5159",
"diff_url": "https://github.com/huggingface/datasets/pull/5159.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5159.patch",
"merged_at": "2022-11-03T20:48:53"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5158 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5158/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5158/comments | https://api.github.com/repos/huggingface/datasets/issues/5158/events | https://github.com/huggingface/datasets/issues/5158 | 1,422,059,287 | I_kwDODunzps5UwucX | 5,158 | Fix language and license tag names in all Hub datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"There are currently 402 datasets with deprecated \"languages\" or \"licenses\".",
"hey @albertvillanova ,i would love to work on this issue if you like.",
"Hi @ayushthe1, thanks for your offer.\r\n\r\nBut as you can see, I self-assigned this issue.\r\n\r\nI have already fixed 200 out of the 402 datasets. My sc... | 2022-10-25T08:19:29 | 2022-10-25T11:27:26 | 2022-10-25T10:42:19 | MEMBER | null | While working on this:
- #5137
we realized there are still many datasets with deprecated "languages" and "licenses" tag names (instead of "language" and "license").
This is a blocking issue: no subsequent PR can be opened to modify their metadata: a ValueError will be thrown.
We should fix the "language" and "license" tag names in all Hub datasets.
TODO:
- [x] Fix language and license tag names in 402 Hub datasets
CC: @julien-c | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5158/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5158/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5157 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5157/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5157/comments | https://api.github.com/repos/huggingface/datasets/issues/5157/events | https://github.com/huggingface/datasets/issues/5157 | 1,421,703,577 | I_kwDODunzps5UvXmZ | 5,157 | Consistent caching between python and jupyter | {
"login": "gpucce",
"id": 32967787,
"node_id": "MDQ6VXNlcjMyOTY3Nzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/32967787?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gpucce",
"html_url": "https://github.com/gpucce",
"followers_url": "https://api.github.com/users/gpucce/followers",
"following_url": "https://api.github.com/users/gpucce/following{/other_user}",
"gists_url": "https://api.github.com/users/gpucce/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gpucce/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gpucce/subscriptions",
"organizations_url": "https://api.github.com/users/gpucce/orgs",
"repos_url": "https://api.github.com/users/gpucce/repos",
"events_url": "https://api.github.com/users/gpucce/events{/privacy}",
"received_events_url": "https://api.github.com/users/gpucce/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "gpucce",
"id": 32967787,
"node_id": "MDQ6VXNlcjMyOTY3Nzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/32967787?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gpucce",
"html_url": "https://github.com/gpucce",
"followers_url": "https://api.github.com/users/gpucce/followers",
"following_url": "https://api.github.com/users/gpucce/following{/other_user}",
"gists_url": "https://api.github.com/users/gpucce/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gpucce/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gpucce/subscriptions",
"organizations_url": "https://api.github.com/users/gpucce/orgs",
"repos_url": "https://api.github.com/users/gpucce/repos",
"events_url": "https://api.github.com/users/gpucce/events{/privacy}",
"received_events_url": "https://api.github.com/users/gpucce/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "gpucce",
"id": 32967787,
"node_id": "MDQ6VXNlcjMyOTY3Nzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/32967787?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gpucce",
"html_url": "https://github.com/gpucce",
"followers_url": "https://api.github... | null | [
"Hi ! Maybe it's possible to have a consistent hash for a function defined in `__main__` and a function define in a notebook.\r\n\r\nHowever for functions imported from another location, pickle uses the location to identify the code, so in that case we can't do much I believe.\r\n\r\nWould it be ok for you if we on... | 2022-10-25T01:34:33 | 2022-11-02T15:43:22 | 2022-11-02T15:43:22 | CONTRIBUTOR | null | ### Feature request
I hope this is not my mistake, currently if I use `load_dataset` from a python session on a custom dataset to do the preprocessing, it will be saved in the cache and in other python sessions it will be loaded from the cache, however calling the same from a jupyter notebook does not work, meaning the preprocessing starts from scratch.
If adjusting the hashes is impossible, is there a way to manually set dataset fingerprint to "force" this behaviour?
### Motivation
If this is not already the case and I am doing something wrong, it would be useful to have the two fingerprints consistent so one can create the dataset once and then try small things on jupyter without preprocessing everything again.
### Your contribution
I am happy to try a PR if you give me some pointers where the changes should happen | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5157/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5157/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5156 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5156/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5156/comments | https://api.github.com/repos/huggingface/datasets/issues/5156/events | https://github.com/huggingface/datasets/issues/5156 | 1,421,667,125 | I_kwDODunzps5UvOs1 | 5,156 | Unable to download dataset using Azure Data Lake Gen 2 | {
"login": "clarissesimoes",
"id": 87379512,
"node_id": "MDQ6VXNlcjg3Mzc5NTEy",
"avatar_url": "https://avatars.githubusercontent.com/u/87379512?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clarissesimoes",
"html_url": "https://github.com/clarissesimoes",
"followers_url": "https://api.github.com/users/clarissesimoes/followers",
"following_url": "https://api.github.com/users/clarissesimoes/following{/other_user}",
"gists_url": "https://api.github.com/users/clarissesimoes/gists{/gist_id}",
"starred_url": "https://api.github.com/users/clarissesimoes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/clarissesimoes/subscriptions",
"organizations_url": "https://api.github.com/users/clarissesimoes/orgs",
"repos_url": "https://api.github.com/users/clarissesimoes/repos",
"events_url": "https://api.github.com/users/clarissesimoes/events{/privacy}",
"received_events_url": "https://api.github.com/users/clarissesimoes/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! From the `adlfs` docs, there are two filesystems you can use:\r\n> To use the Gen1 filesystem:\r\n> - known_implementations[‘adl’] = {‘class’: ‘adlfs.AzureDatalakeFileSystem’}\r\n> \r\n> To use the Gen2 filesystem:\r\n> - known_implementations[‘abfs’] = {‘class’: ‘adlfs.AzureBlobFileSystem’}\r\n\r\nIf I'm no... | 2022-10-25T00:43:18 | 2022-11-17T23:37:09 | 2022-11-17T23:37:08 | NONE | null | ### Describe the bug
When using the DatasetBuilder method with the credentials for the cloud storage Azure Data Lake (adl) Gen2, the following error is showed:
```
Traceback (most recent call last):
File "download_hf_dataset.py", line 143, in <module>
main()
File "download_hf_dataset.py", line 102, in main
builder.download_and_prepare(save_dir, storage_options=storage_options, max_shard_size="250MB", file_format="parquet")
File "/home/clarisses/miniconda3/envs/hf_datasets_env/lib/python3.8/site-packages/datasets/builder.py", line 671, in download_and_prepare
fs_token_paths = fsspec.get_fs_token_paths(output_dir, storage_options=storage_options)
File "/home/clarisses/miniconda3/envs/hf_datasets_env/lib/python3.8/site-packages/fsspec/core.py", line 639, in get_fs_token_paths
fs = cls(**options)
File "/home/clarisses/miniconda3/envs/hf_datasets_env/lib/python3.8/site-packages/fsspec/spec.py", line 76, in __call__
obj = super().__call__(*args, **kwargs)
TypeError: __init__() got an unexpected keyword argument 'account_name'
```
If I don't pass the storage_options argument (leave it as None), it requires the credentials used in ADL Gen 1:
`TypeError: __init__() missing 3 required positional arguments: 'tenant_id', 'client_id', and 'client_secret'`
Thus, it is not possible to download a dataset from the cloud using Azure Data Lake (adl) Gen2.
### Steps to reproduce the bug
Assuming that you have an account on Azure and at Storage Account that can be used for reproduce:
1. Create a dict with the format to connect to Azure Data Lake Gen 2
```
storage_options = {"account_name": ACCOUNT_NAME, "account_key": ACCOUNT_KEY) # gen 2 filesystem
```
2. Create a dataset builder for any HF hosted dataset
```
builder = load_dataset_builder(dataset_name)
```
3. Try to download the dataset passing the storage_options as an argument
```
save_dir = 'adl://my_save_dir'
builder.download_and_prepare(save_dir, storage_options=storage_options, max_shard_size="250MB", file_format="parquet")
```
### Expected behavior
Not seeing the error mentioned above and being able to download the dataset to the provided path on ADL
### Environment info
- `datasets` version: 2.6.1
- Platform: Linux-5.15.0-46-generic-x86_64-with-glibc2.17
- Python version: 3.8.13
- PyArrow version: 9.0.0
- Pandas version: 1.5.1 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5156/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5156/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5155 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5155/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5155/comments | https://api.github.com/repos/huggingface/datasets/issues/5155/events | https://github.com/huggingface/datasets/pull/5155 | 1,421,278,748 | PR_kwDODunzps5BcCYr | 5,155 | TextConfig: added "errors" | {
"login": "NightMachinery",
"id": 36224762,
"node_id": "MDQ6VXNlcjM2MjI0NzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/36224762?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NightMachinery",
"html_url": "https://github.com/NightMachinery",
"followers_url": "https://api.github.com/users/NightMachinery/followers",
"following_url": "https://api.github.com/users/NightMachinery/following{/other_user}",
"gists_url": "https://api.github.com/users/NightMachinery/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NightMachinery/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NightMachinery/subscriptions",
"organizations_url": "https://api.github.com/users/NightMachinery/orgs",
"repos_url": "https://api.github.com/users/NightMachinery/repos",
"events_url": "https://api.github.com/users/NightMachinery/events{/privacy}",
"received_events_url": "https://api.github.com/users/NightMachinery/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-24T18:56:52 | 2022-11-03T13:38:13 | 2022-11-03T13:35:35 | CONTRIBUTOR | null | This patch adds the ability to set the `errors` option of `open` for loading text datasets. I needed it because some data I had scraped had bad bytes in it, so I needed `errors='ignore'`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5155/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5155/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5155",
"html_url": "https://github.com/huggingface/datasets/pull/5155",
"diff_url": "https://github.com/huggingface/datasets/pull/5155.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5155.patch",
"merged_at": "2022-11-03T13:35:35"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5154 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5154/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5154/comments | https://api.github.com/repos/huggingface/datasets/issues/5154/events | https://github.com/huggingface/datasets/pull/5154 | 1,421,161,992 | PR_kwDODunzps5BbpQZ | 5,154 | Test latest fsspec in CI | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-24T17:18:13 | 2022-10-25T09:32:51 | 2022-10-25T09:30:45 | MEMBER | null | Following the discussion in https://discuss.huggingface.co/t/attributeerror-module-fsspec-has-no-attribute-asyn/19255 I think we need to test the latest fsspec in the CI | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5154/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5154/timeline | null | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5154",
"html_url": "https://github.com/huggingface/datasets/pull/5154",
"diff_url": "https://github.com/huggingface/datasets/pull/5154.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5154.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5153 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5153/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5153/comments | https://api.github.com/repos/huggingface/datasets/issues/5153/events | https://github.com/huggingface/datasets/issues/5153 | 1,420,833,457 | I_kwDODunzps5UsDKx | 5,153 | default Image/AudioFolder infers labels when there is no metadata files even if there is only one dir | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "... | null | [
"Makes sense! For the last structure, we could count the path segments (delimited by \"/\" for URLs and `os.sep` for local paths) to ensure all inferred labels are on the same level. Otherwise, I think it's safe to assume they are meaningless and ignore them.\r\n"
] | 2022-10-24T13:28:18 | 2022-11-15T16:31:10 | 2022-11-15T16:31:09 | CONTRIBUTOR | null | ### Describe the bug
By default FolderBasedBuilder infers labels if there is not metadata files, even if it's meaningless (for example, they are in a single directory or in the root folder, see this repo as an example: https://huggingface.co/datasets/patrickvonplaten/audios
As this is a corner case for quick exploration of images or audios on the Hub.
### Steps to reproduce the bug
If you have directory like this:
```
repo
image1.jpg
image2.jpg
image3.jpg
```
or
```
repo
data
image1.jpg
image2.jpg
image3.jpg
```
doing `ds = load_dataset(repo)` would create `label` feature:
```python
print(ds["train"][0])
>> {'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x375 at 0x7FB5326468E0>, 'label': 0}
```
Also, if you have the following structure:
```
repo
data
image1.jpg
image2.jpg
image3.jpg
image4.jpg
image5.jpg
image6.jpg
```
it will infer two labels:
```python
print(ds["train"][0])
print(ds["train"][-1])
>> {'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x375 at 0x7FB5326468E0>, 'label': 1}
>> {'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x415 at 0x7FB5326555B0>, 'label': 0}
```
### Expected behavior
We should have only one base feature (Image/Audio) in such cases.
### Environment info
all versions of `datasets` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5153/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5153/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5149 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5149/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5149/comments | https://api.github.com/repos/huggingface/datasets/issues/5149/events | https://github.com/huggingface/datasets/pull/5149 | 1,420,415,639 | PR_kwDODunzps5BZJab | 5,149 | Make iter_files deterministic | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-24T08:16:27 | 2022-10-27T09:53:23 | 2022-10-27T09:51:09 | MEMBER | null | Fix #5145. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5149/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5149/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5149",
"html_url": "https://github.com/huggingface/datasets/pull/5149",
"diff_url": "https://github.com/huggingface/datasets/pull/5149.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5149.patch",
"merged_at": "2022-10-27T09:51:09"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5148 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5148/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5148/comments | https://api.github.com/repos/huggingface/datasets/issues/5148/events | https://github.com/huggingface/datasets/issues/5148 | 1,420,219,222 | I_kwDODunzps5UptNW | 5,148 | Cannot find the rvl_cdip dataset | {
"login": "santule",
"id": 20509836,
"node_id": "MDQ6VXNlcjIwNTA5ODM2",
"avatar_url": "https://avatars.githubusercontent.com/u/20509836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/santule",
"html_url": "https://github.com/santule",
"followers_url": "https://api.github.com/users/santule/followers",
"following_url": "https://api.github.com/users/santule/following{/other_user}",
"gists_url": "https://api.github.com/users/santule/gists{/gist_id}",
"starred_url": "https://api.github.com/users/santule/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/santule/subscriptions",
"organizations_url": "https://api.github.com/users/santule/orgs",
"repos_url": "https://api.github.com/users/santule/repos",
"events_url": "https://api.github.com/users/santule/events{/privacy}",
"received_events_url": "https://api.github.com/users/santule/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi, @santule.\r\n\r\nWe have transferred all dataset scripts from GitHub to the Hugging Face Hub: https://huggingface.co/datasets\r\n- Concretely, you have \"rvl_cdip\" here: https://huggingface.co/datasets/rvl_cdip\r\n\r\nTo be able to load them, you should update your `datasets` library:\r\n```\r\npip install -U... | 2022-10-24T04:57:42 | 2022-10-24T12:23:47 | 2022-10-24T06:25:28 | NONE | null | Hi,
I am trying to use load_dataset to load the official "rvl_cdip" dataset but getting an error.
dataset = load_dataset("rvl_cdip")
Couldn't find 'rvl_cdip' on the Hugging Face Hub either: FileNotFoundError: Couldn't find the file at https://raw.githubusercontent.com/huggingface/datasets/master/datasets/rvl_cdip/rvl_cdip.py
Regards,
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5148/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5148/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5146 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5146/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5146/comments | https://api.github.com/repos/huggingface/datasets/issues/5146/events | https://github.com/huggingface/datasets/pull/5146 | 1,418,331,282 | PR_kwDODunzps5BSUWW | 5,146 | Delete duplicate issue template file | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-21T13:18:46 | 2022-10-21T13:52:30 | 2022-10-21T13:50:04 | MEMBER | null | A conflict between two PRs:
- #5116
- #5136
was not properly resolved, resulting in a duplicate issue template.
This PR removes the duplicate template. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5146/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5146/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5146",
"html_url": "https://github.com/huggingface/datasets/pull/5146",
"diff_url": "https://github.com/huggingface/datasets/pull/5146.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5146.patch",
"merged_at": "2022-10-21T13:50:04"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5145 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5145/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5145/comments | https://api.github.com/repos/huggingface/datasets/issues/5145/events | https://github.com/huggingface/datasets/issues/5145 | 1,418,005,452 | I_kwDODunzps5UhQvM | 5,145 | Dataset order is not deterministic with ZIP archives and `iter_files` | {
"login": "fxmarty",
"id": 9808326,
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fxmarty",
"html_url": "https://github.com/fxmarty",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https://api.github.com/users/fxmarty/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fxmarty/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fxmarty/subscriptions",
"organizations_url": "https://api.github.com/users/fxmarty/orgs",
"repos_url": "https://api.github.com/users/fxmarty/repos",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"received_events_url": "https://api.github.com/users/fxmarty/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Thanks for reporting ! The issue doesn't come from shuffling, but from `beans` row order not being deterministic:\r\n\r\nhttps://huggingface.co/datasets/beans/blob/main/beans.py uses `dl_manager.iter_files` on ZIP archives and the file order doesn't seen to be deterministic and changes across machines",
"Thank y... | 2022-10-21T09:00:03 | 2022-10-27T09:51:49 | 2022-10-27T09:51:10 | CONTRIBUTOR | null | ### Describe the bug
For the `beans` dataset (did not try on other), the order of samples is not the same on different machines. Tested on my local laptop, github actions machine, and ec2 instance. The three yield a different order.
### Steps to reproduce the bug
In a clean docker container or conda environment with datasets==2.6.1, run
```python
from datasets import load_dataset
from pprint import pprint
data = load_dataset("beans", split="validation")
pprint(data["image_file_path"])
```
### Expected behavior
The order of the images is the same on all machines.
### Environment info
On the EC2 instance:
```
- `datasets` version: 2.6.1
- Platform: Linux-4.14.291-218.527.amzn2.x86_64-x86_64-with-glibc2.2.5
- Python version: 3.7.10
- PyArrow version: 9.0.0
- Pandas version: 1.3.5
- Numpy version: not checked
```
On my local laptop:
```
- `datasets` version: 2.6.1
- Platform: Linux-5.15.0-50-generic-x86_64-with-glibc2.35
- Python version: 3.9.12
- PyArrow version: 7.0.0
- Pandas version: 1.3.5
- Numpy version: 1.23.1
```
On github actions:
```
- `datasets` version: 2.6.1
- Platform: Linux-5.15.0-1022-azure-x86_64-with-glibc2.2.5
- Python version: 3.8.14
- PyArrow version: 9.0.0
- Pandas version: 1.5.1
- Numpy version: 1.23.4
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5145/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5145/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5144 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5144/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5144/comments | https://api.github.com/repos/huggingface/datasets/issues/5144/events | https://github.com/huggingface/datasets/issues/5144 | 1,417,974,731 | I_kwDODunzps5UhJPL | 5,144 | Inconsistent documentation on map remove_columns | {
"login": "zhaowei-wang-nlp",
"id": 22047467,
"node_id": "MDQ6VXNlcjIyMDQ3NDY3",
"avatar_url": "https://avatars.githubusercontent.com/u/22047467?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhaowei-wang-nlp",
"html_url": "https://github.com/zhaowei-wang-nlp",
"followers_url": "https://api.github.com/users/zhaowei-wang-nlp/followers",
"following_url": "https://api.github.com/users/zhaowei-wang-nlp/following{/other_user}",
"gists_url": "https://api.github.com/users/zhaowei-wang-nlp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhaowei-wang-nlp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhaowei-wang-nlp/subscriptions",
"organizations_url": "https://api.github.com/users/zhaowei-wang-nlp/orgs",
"repos_url": "https://api.github.com/users/zhaowei-wang-nlp/repos",
"events_url": "https://api.github.com/users/zhaowei-wang-nlp/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhaowei-wang-nlp/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
},
{
"id": 19358928... | closed | false | null | [] | null | [
"Thanks for reporting, @zhaowei-wang-nlp.\r\n\r\nYou are right, the documentation is confusing on the behavior of `remove_columns`. We should better explain it. ",
"This is a duplicate of https://github.com/huggingface/datasets/issues/2343.",
"I'm closing this issue because as @mariosasko pointed out, it is a d... | 2022-10-21T08:37:53 | 2022-11-15T14:15:10 | 2022-11-15T14:15:10 | NONE | null | ### Describe the bug
The page [process](https://huggingface.co/docs/datasets/process) says this about the parameter `remove_columns` of the function `map`:
When you remove a column, it is only removed after the example has been provided to the mapped function.
So it seems that the `remove_columns` parameter removes after the mapped functions.
However, another page, [the documentation of the function map](https://huggingface.co/docs/datasets/v2.6.1/en/package_reference/main_classes#datasets.Dataset.map.remove_columns) says:
Columns will be removed before updating the examples with the output of `function`, i.e. if `function` is adding columns with names in remove_columns, these columns will be kept.
So one page says "after the mapped function" and another says "before the mapped function."
Is there something wrong?
### Steps to reproduce the bug
Not about code.
### Expected behavior
consistent about the descriptions of the behavior of the parameter `remove_columns` in the function `map`.
### Environment info
datasets V2.6.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5144/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5144/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5143 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5143/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5143/comments | https://api.github.com/repos/huggingface/datasets/issues/5143/events | https://github.com/huggingface/datasets/issues/5143 | 1,416,837,186 | I_kwDODunzps5UczhC | 5,143 | DownloadManager Git LFS support | {
"login": "Muennighoff",
"id": 62820084,
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Muennighoff",
"html_url": "https://github.com/Muennighoff",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_url": "https://api.github.com/users/Muennighoff/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Muennighoff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Muennighoff/subscriptions",
"organizations_url": "https://api.github.com/users/Muennighoff/orgs",
"repos_url": "https://api.github.com/users/Muennighoff/repos",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"received_events_url": "https://api.github.com/users/Muennighoff/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Hey ! Actually it works, just pass the right URL ;)\r\nThe URL must be the one with “/resolve/”\r\n\r\ne.g. https://huggingface.co/datasets/imagenet-1k/resolve/main/data/test_images.tar.gz\r\n\r\nYou can even pass a relative path to the dl_manager instead, like `dl_manager.download(\"data/test_images.tar.gz\")`",
... | 2022-10-20T15:29:29 | 2022-10-20T17:17:10 | 2022-10-20T17:17:10 | CONTRIBUTOR | null | ### Feature request
Maybe I'm mistaken but the `DownloadManager` does not support extracting git lfs files out of the box right?
Using `dl_manager.download()` or `dl_manager.download_and_extract()` still returns lfs files afaict.
Is there a good way to write a dataset loading script for a repo with lfs files?
### Motivation
/
### Your contribution
/ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5143/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5143/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5142 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5142/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5142/comments | https://api.github.com/repos/huggingface/datasets/issues/5142/events | https://github.com/huggingface/datasets/pull/5142 | 1,416,317,678 | PR_kwDODunzps5BLd90 | 5,142 | Deprecate num_proc parameter in DownloadManager.extract | {
"login": "ayushthe1",
"id": 114604338,
"node_id": "U_kgDOBtS5Mg",
"avatar_url": "https://avatars.githubusercontent.com/u/114604338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ayushthe1",
"html_url": "https://github.com/ayushthe1",
"followers_url": "https://api.github.com/users/ayushthe1/followers",
"following_url": "https://api.github.com/users/ayushthe1/following{/other_user}",
"gists_url": "https://api.github.com/users/ayushthe1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ayushthe1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ayushthe1/subscriptions",
"organizations_url": "https://api.github.com/users/ayushthe1/orgs",
"repos_url": "https://api.github.com/users/ayushthe1/repos",
"events_url": "https://api.github.com/users/ayushthe1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ayushthe1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-20T09:52:52 | 2022-10-25T18:06:56 | 2022-10-25T15:56:45 | CONTRIBUTOR | null | fixes #5132 : Deprecated the `num_proc` parameter in `DownloadManager.extract` by passing `num_proc` parameter to `map_nested` . | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5142/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5142/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5142",
"html_url": "https://github.com/huggingface/datasets/pull/5142",
"diff_url": "https://github.com/huggingface/datasets/pull/5142.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5142.patch",
"merged_at": "2022-10-25T15:56:45"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5141 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5141/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5141/comments | https://api.github.com/repos/huggingface/datasets/issues/5141/events | https://github.com/huggingface/datasets/pull/5141 | 1,415,479,438 | PR_kwDODunzps5BIp1l | 5,141 | Raise ImportError instead of OSError | {
"login": "ayushthe1",
"id": 114604338,
"node_id": "U_kgDOBtS5Mg",
"avatar_url": "https://avatars.githubusercontent.com/u/114604338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ayushthe1",
"html_url": "https://github.com/ayushthe1",
"followers_url": "https://api.github.com/users/ayushthe1/followers",
"following_url": "https://api.github.com/users/ayushthe1/following{/other_user}",
"gists_url": "https://api.github.com/users/ayushthe1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ayushthe1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ayushthe1/subscriptions",
"organizations_url": "https://api.github.com/users/ayushthe1/orgs",
"repos_url": "https://api.github.com/users/ayushthe1/repos",
"events_url": "https://api.github.com/users/ayushthe1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ayushthe1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-19T19:30:05 | 2022-10-25T15:59:25 | 2022-10-25T15:56:58 | CONTRIBUTOR | null | fixes #5134 : Replaced OSError with ImportError if required extraction library is not installed. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5141/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5141/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5141",
"html_url": "https://github.com/huggingface/datasets/pull/5141",
"diff_url": "https://github.com/huggingface/datasets/pull/5141.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5141.patch",
"merged_at": "2022-10-25T15:56:58"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5140 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5140/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5140/comments | https://api.github.com/repos/huggingface/datasets/issues/5140/events | https://github.com/huggingface/datasets/pull/5140 | 1,415,075,530 | PR_kwDODunzps5BHTNq | 5,140 | Make the KeyHasher FIPS compliant | {
"login": "vvalouch",
"id": 22592860,
"node_id": "MDQ6VXNlcjIyNTkyODYw",
"avatar_url": "https://avatars.githubusercontent.com/u/22592860?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vvalouch",
"html_url": "https://github.com/vvalouch",
"followers_url": "https://api.github.com/users/vvalouch/followers",
"following_url": "https://api.github.com/users/vvalouch/following{/other_user}",
"gists_url": "https://api.github.com/users/vvalouch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vvalouch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vvalouch/subscriptions",
"organizations_url": "https://api.github.com/users/vvalouch/orgs",
"repos_url": "https://api.github.com/users/vvalouch/repos",
"events_url": "https://api.github.com/users/vvalouch/events{/privacy}",
"received_events_url": "https://api.github.com/users/vvalouch/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-19T14:25:52 | 2022-11-07T16:20:43 | 2022-11-07T16:20:43 | NONE | null | MD5 is not FIPS compliant thus I am proposing this minimal change to make datasets package FIPS compliant | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5140/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5140/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5140",
"html_url": "https://github.com/huggingface/datasets/pull/5140",
"diff_url": "https://github.com/huggingface/datasets/pull/5140.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5140.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5137 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5137/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5137/comments | https://api.github.com/repos/huggingface/datasets/issues/5137/events | https://github.com/huggingface/datasets/issues/5137 | 1,414,642,723 | I_kwDODunzps5UUbwj | 5,137 | Align task tags in dataset metadata | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"I removed all the invalid task_ids in datasts without namespace, based on the <s>(internal)</s> types.ts",
"(Types.ts is not internal it's public)",
"I have opened PRs to fix the task_ids in all datasets within a namespace as well.\r\n\r\nWorking on task_categories...",
"For future reference: this fix had so... | 2022-10-19T09:41:42 | 2022-11-10T05:25:58 | 2022-10-25T06:17:00 | MEMBER | null | ## Describe
Once we have agreed on a common naming for task tags for all open source projects, we should align on them.
## Steps
- [x] Align task tags in canonical datasets
- [x] task_categories: 4 datasets
- [x] task_ids (by @lhoestq)
- [x] Open PRs in community datasets
- [x] task_categories: 451 datasets
- [x] task_ids: 556 datasets
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5137/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5137/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5136 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5136/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5136/comments | https://api.github.com/repos/huggingface/datasets/issues/5136/events | https://github.com/huggingface/datasets/pull/5136 | 1,414,492,139 | PR_kwDODunzps5BFWMG | 5,136 | Update docs once dataset scripts transferred to the Hub | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-19T07:58:27 | 2022-10-20T08:12:21 | 2022-10-20T08:10:00 | MEMBER | null | Todo:
- [x] Update docs:
- [x] Datasets on GitHub (legacy)
- [x] Load: offline
- [x] About dataset load:
- [x] Maintaining integrity
- [x] Security
- [x] Update docstrings:
- [x] Inspect:
- [x] get_dataset_config_info
- [x] get_dataset_split_names
- [x] Load:
- [x] dataset_module_factory
- [x] load_dataset_builder
- [x] load_dataset
- [x] Remove `ADD_NEW_DATASET.md`
- [x] Update `.github/ISSUE_TEMPLATE/config.yml`
Fix #5135. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5136/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5136/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5136",
"html_url": "https://github.com/huggingface/datasets/pull/5136",
"diff_url": "https://github.com/huggingface/datasets/pull/5136.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5136.patch",
"merged_at": "2022-10-20T08:10:00"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5135 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5135/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5135/comments | https://api.github.com/repos/huggingface/datasets/issues/5135/events | https://github.com/huggingface/datasets/issues/5135 | 1,414,413,519 | I_kwDODunzps5UTjzP | 5,135 | Update docs once dataset scripts transferred to the Hub | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2022-10-19T06:58:19 | 2022-10-20T08:10:01 | 2022-10-20T08:10:01 | MEMBER | null | ## Describe the bug
As discussed in:
- https://github.com/huggingface/hub-docs/pull/423#pullrequestreview-1146083701
we should update our docs once dataset scripts have been transferred to the Hub (and removed from GitHub):
- #4974
Concretely:
- [x] Datasets on GitHub (legacy): https://huggingface.co/docs/datasets/main/en/share#datasets-on-github-legacy
- [x] ADD_NEW_DATASET: https://github.com/huggingface/datasets/blob/main/ADD_NEW_DATASET.md
- ...
This PR complements the work of:
- #5067
This PR is a follow-up of PRs:
- #3777
CC: @julien-c | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5135/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5135/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5134 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5134/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5134/comments | https://api.github.com/repos/huggingface/datasets/issues/5134/events | https://github.com/huggingface/datasets/issues/5134 | 1,413,623,687 | I_kwDODunzps5UQi-H | 5,134 | Raise ImportError instead of OSError if required extraction library is not installed | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | closed | false | {
"login": "ayushthe1",
"id": 114604338,
"node_id": "U_kgDOBtS5Mg",
"avatar_url": "https://avatars.githubusercontent.com/u/114604338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ayushthe1",
"html_url": "https://github.com/ayushthe1",
"followers_url": "https://api.github.com/users/ayushthe1/followers",
"following_url": "https://api.github.com/users/ayushthe1/following{/other_user}",
"gists_url": "https://api.github.com/users/ayushthe1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ayushthe1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ayushthe1/subscriptions",
"organizations_url": "https://api.github.com/users/ayushthe1/orgs",
"repos_url": "https://api.github.com/users/ayushthe1/repos",
"events_url": "https://api.github.com/users/ayushthe1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ayushthe1/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "ayushthe1",
"id": 114604338,
"node_id": "U_kgDOBtS5Mg",
"avatar_url": "https://avatars.githubusercontent.com/u/114604338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ayushthe1",
"html_url": "https://github.com/ayushthe1",
"followers_url": "https://api.git... | null | [
"hey ,i would like to work on this issue . Please assign it to me.",
"hey @mariosasko , i made a pr for this issue. Could you please review it.\r\nAlso i found multiple `OSError` in `extract.py` file which i thought could be replaced too but wasn't sure about them.\r\nPlease do tell if that also needs to be done.... | 2022-10-18T17:53:46 | 2022-10-25T15:56:59 | 2022-10-25T15:56:59 | CONTRIBUTOR | null | According to the official Python docs, `OSError` should be thrown in the following situations:
> This exception is raised when a system function returns a system-related error, including I/O failures such as “file not found” or “disk full” (not for illegal argument types or other incidental errors).
Hence, it makes more sense to raise `ImportError` instead of `OSError` when the required extraction/decompression library is not installed. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5134/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5134/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5133 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5133/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5133/comments | https://api.github.com/repos/huggingface/datasets/issues/5133/events | https://github.com/huggingface/datasets/issues/5133 | 1,413,623,462 | I_kwDODunzps5UQi6m | 5,133 | Tensor operation not functioning in dataset mapping | {
"login": "xinghaow99",
"id": 50691954,
"node_id": "MDQ6VXNlcjUwNjkxOTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/50691954?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xinghaow99",
"html_url": "https://github.com/xinghaow99",
"followers_url": "https://api.github.com/users/xinghaow99/followers",
"following_url": "https://api.github.com/users/xinghaow99/following{/other_user}",
"gists_url": "https://api.github.com/users/xinghaow99/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xinghaow99/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xinghaow99/subscriptions",
"organizations_url": "https://api.github.com/users/xinghaow99/orgs",
"repos_url": "https://api.github.com/users/xinghaow99/repos",
"events_url": "https://api.github.com/users/xinghaow99/events{/privacy}",
"received_events_url": "https://api.github.com/users/xinghaow99/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! The Torch ops in your snippet are not equivalent to the NumPy ones, hence the difference. You can get the same behavior by replacing the line `feature = torch.mean(feature, dim=1)` with `feature = feature.squeeze().mean(1)` .",
"> Hi! The Torch ops in your snippet are not equivalent to the NumPy ones, hence ... | 2022-10-18T17:53:35 | 2022-10-19T04:15:45 | 2022-10-19T04:15:44 | NONE | null | ## Describe the bug
I'm doing a torch.mean() operation in data preprocessing, and it's not working.
## Steps to reproduce the bug
```
from transformers import pipeline
import torch
import numpy as np
from datasets import load_dataset
device = 'cuda:0'
raw_dataset = load_dataset("glue", "sst2")
feature_extraction = pipeline('feature-extraction', 'bert-base-uncased', device=device)
def extracted_data(examples):
# feature = torch.tensor(feature_extraction(examples['sentence'], batch_size=16), device=device)
# feature = torch.mean(feature, dim=1)
feature = np.asarray(feature_extraction(examples['sentence'], batch_size=16)).squeeze().mean(1)
print(feature.shape)
return {'feature': feature}
extracted_dataset = raw_dataset.map(extracted_data, batched=True, batch_size=16)
```
## Results
When running with torch.mean(), the shape printed out is [16, seq_len, 768], which is exactly the same before the operation. While numpy works just fine, which gives [16, 768].
## Environment info
- `datasets` version: 2.6.1
- Platform: Linux-4.4.0-142-generic-x86_64-with-glibc2.31
- Python version: 3.10.6
- PyArrow version: 9.0.0
- Pandas version: 1.5.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5133/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5133/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5132 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5132/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5132/comments | https://api.github.com/repos/huggingface/datasets/issues/5132/events | https://github.com/huggingface/datasets/issues/5132 | 1,413,607,306 | I_kwDODunzps5UQe-K | 5,132 | Depracate `num_proc` parameter in `DownloadManager.extract` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | closed | false | {
"login": "ayushthe1",
"id": 114604338,
"node_id": "U_kgDOBtS5Mg",
"avatar_url": "https://avatars.githubusercontent.com/u/114604338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ayushthe1",
"html_url": "https://github.com/ayushthe1",
"followers_url": "https://api.github.com/users/ayushthe1/followers",
"following_url": "https://api.github.com/users/ayushthe1/following{/other_user}",
"gists_url": "https://api.github.com/users/ayushthe1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ayushthe1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ayushthe1/subscriptions",
"organizations_url": "https://api.github.com/users/ayushthe1/orgs",
"repos_url": "https://api.github.com/users/ayushthe1/repos",
"events_url": "https://api.github.com/users/ayushthe1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ayushthe1/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "ayushthe1",
"id": 114604338,
"node_id": "U_kgDOBtS5Mg",
"avatar_url": "https://avatars.githubusercontent.com/u/114604338?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ayushthe1",
"html_url": "https://github.com/ayushthe1",
"followers_url": "https://api.git... | null | [
"I can take this! #self-assign",
"#self-assign",
"@lazarust i'm already working on this issue :smile: ",
"#self-assign",
"hey @mariosasko , i made a pr for this issue. Could you please review it."
] | 2022-10-18T17:41:05 | 2022-10-25T15:56:46 | 2022-10-25T15:56:46 | CONTRIBUTOR | null | The `num_proc` parameter is only present in `DownloadManager.extract` but not in `StreamingDownloadManager.extract`, making it impossible to support streaming in the dataset scripts that use it (`openwebtext` and `the_pile_stack_exchange`). We can avoid this situation by deprecating this parameter and passing `DownloadConfig`'s `num_proc` to `map_nested` instead, as it's done in `DownloadManager.download`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5132/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5132/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5130 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5130/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5130/comments | https://api.github.com/repos/huggingface/datasets/issues/5130/events | https://github.com/huggingface/datasets/pull/5130 | 1,413,435,000 | PR_kwDODunzps5BBxXX | 5,130 | Avoid extra cast in `class_encode_column` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-18T15:31:24 | 2022-10-19T11:53:02 | 2022-10-19T11:50:46 | CONTRIBUTOR | null | Pass the updated features to `map` to avoid the `cast` in `class_encode_column`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5130/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5130/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5130",
"html_url": "https://github.com/huggingface/datasets/pull/5130",
"diff_url": "https://github.com/huggingface/datasets/pull/5130.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5130.patch",
"merged_at": "2022-10-19T11:50:46"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5129 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5129/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5129/comments | https://api.github.com/repos/huggingface/datasets/issues/5129/events | https://github.com/huggingface/datasets/issues/5129 | 1,413,031,664 | I_kwDODunzps5UOSbw | 5,129 | unexpected `cast` or `class_encode_column` result after `rename_column` | {
"login": "quaeast",
"id": 35144675,
"node_id": "MDQ6VXNlcjM1MTQ0Njc1",
"avatar_url": "https://avatars.githubusercontent.com/u/35144675?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/quaeast",
"html_url": "https://github.com/quaeast",
"followers_url": "https://api.github.com/users/quaeast/followers",
"following_url": "https://api.github.com/users/quaeast/following{/other_user}",
"gists_url": "https://api.github.com/users/quaeast/gists{/gist_id}",
"starred_url": "https://api.github.com/users/quaeast/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/quaeast/subscriptions",
"organizations_url": "https://api.github.com/users/quaeast/orgs",
"repos_url": "https://api.github.com/users/quaeast/repos",
"events_url": "https://api.github.com/users/quaeast/events{/privacy}",
"received_events_url": "https://api.github.com/users/quaeast/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi! Unfortunately, I can't reproduce this issue locally (in Python 3.7/3.10) or in Colab. I would assume this is due to a bug we fixed in the latest release, but your version is up-to-date, so I'm not sure if there is something we can do to help...",
"Hi, 方子东. I tried running the code with exact the same configu... | 2022-10-18T11:15:24 | 2022-10-19T03:02:26 | 2022-10-19T03:02:26 | NONE | null | ## Describe the bug
When invoke `cast` or `class_encode_column` to a colunm renamed by `rename_column` , it will convert all the variables in this column into one variable. I also run this script in version 2.5.2, this bug does not appear. So I switched to the older version.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("amazon_reviews_multi", "en")
data = dataset['train']
data = data.remove_columns(
[
"review_id",
"product_id",
"reviewer_id",
"review_title",
"language",
"product_category",
]
)
data = data.rename_column("review_body", "text")
data1 = data.class_encode_column("stars")
print(set(data1.data.columns[0]))
# output: {<pyarrow.Int64Scalar: 4>, <pyarrow.Int64Scalar: 2>, <pyarrow.Int64Scalar: 3>, <pyarrow.Int64Scalar: 0>, <pyarrow.Int64Scalar: 1>}
data = data.rename_column("stars", "label")
print(set(data.data.columns[0]))
# output: {<pyarrow.Int32Scalar: 5>, <pyarrow.Int32Scalar: 4>, <pyarrow.Int32Scalar: 1>, <pyarrow.Int32Scalar: 3>, <pyarrow.Int32Scalar: 2>}
data2 = data.class_encode_column("label")
print(set(data2.data.columns[0]))
# output: {<pyarrow.Int64Scalar: 0>}
```
## Expected results
the last print should be:
{<pyarrow.Int64Scalar: 4>, <pyarrow.Int64Scalar: 2>, <pyarrow.Int64Scalar: 3>, <pyarrow.Int64Scalar: 0>, <pyarrow.Int64Scalar: 1>}
## Actual results
but it output:
{<pyarrow.Int64Scalar: 0>}
## Environment info
- `datasets` version: 2.6.1
- Platform: macOS-12.5.1-arm64-arm-64bit
- Python version: 3.10.6
- PyArrow version: 9.0.0
- Pandas version: 1.5.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5129/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5129/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5128 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5128/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5128/comments | https://api.github.com/repos/huggingface/datasets/issues/5128/events | https://github.com/huggingface/datasets/pull/5128 | 1,412,783,855 | PR_kwDODunzps5A_k9s | 5,128 | Make filename matching more robust | {
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-18T08:22:48 | 2022-10-28T13:07:38 | 2022-10-28T13:05:06 | CONTRIBUTOR | null | Fix #5046 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5128/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5128/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5128",
"html_url": "https://github.com/huggingface/datasets/pull/5128",
"diff_url": "https://github.com/huggingface/datasets/pull/5128.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5128.patch",
"merged_at": "2022-10-28T13:05:06"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5126 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5126/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5126/comments | https://api.github.com/repos/huggingface/datasets/issues/5126/events | https://github.com/huggingface/datasets/pull/5126 | 1,411,757,124 | PR_kwDODunzps5A8Iw3 | 5,126 | Fix class name of symbolic link | {
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-17T15:11:02 | 2022-11-14T14:40:18 | 2022-11-14T14:40:18 | CONTRIBUTOR | null | Fix #5098 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5126/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5126/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5126",
"html_url": "https://github.com/huggingface/datasets/pull/5126",
"diff_url": "https://github.com/huggingface/datasets/pull/5126.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5126.patch",
"merged_at": "2022-11-14T14:40:18"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5125 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5125/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5125/comments | https://api.github.com/repos/huggingface/datasets/issues/5125/events | https://github.com/huggingface/datasets/pull/5125 | 1,411,602,813 | PR_kwDODunzps5A7nr8 | 5,125 | Add `pyproject.toml` for `black` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-17T13:38:47 | 2022-10-17T14:23:27 | 2022-10-17T14:21:09 | CONTRIBUTOR | null | Add `pyproject.toml` as a config file for the `black` tool to support VS Code's auto-formatting on save (and to be more consistent with the other HF projects).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5125/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5125/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5125",
"html_url": "https://github.com/huggingface/datasets/pull/5125",
"diff_url": "https://github.com/huggingface/datasets/pull/5125.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5125.patch",
"merged_at": "2022-10-17T14:21:09"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5124 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5124/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5124/comments | https://api.github.com/repos/huggingface/datasets/issues/5124/events | https://github.com/huggingface/datasets/pull/5124 | 1,411,159,725 | PR_kwDODunzps5A6HeL | 5,124 | Install tensorflow-macos dependency conditionally | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-17T08:45:08 | 2022-10-19T09:12:17 | 2022-10-19T09:10:06 | MEMBER | null | Fix #5118. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5124/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5124/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5124",
"html_url": "https://github.com/huggingface/datasets/pull/5124",
"diff_url": "https://github.com/huggingface/datasets/pull/5124.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5124.patch",
"merged_at": "2022-10-19T09:10:06"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5122 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5122/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5122/comments | https://api.github.com/repos/huggingface/datasets/issues/5122/events | https://github.com/huggingface/datasets/pull/5122 | 1,410,732,403 | PR_kwDODunzps5A4rWn | 5,122 | Add warning | {
"login": "Salehbigdeli",
"id": 34204311,
"node_id": "MDQ6VXNlcjM0MjA0MzEx",
"avatar_url": "https://avatars.githubusercontent.com/u/34204311?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Salehbigdeli",
"html_url": "https://github.com/Salehbigdeli",
"followers_url": "https://api.github.com/users/Salehbigdeli/followers",
"following_url": "https://api.github.com/users/Salehbigdeli/following{/other_user}",
"gists_url": "https://api.github.com/users/Salehbigdeli/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Salehbigdeli/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Salehbigdeli/subscriptions",
"organizations_url": "https://api.github.com/users/Salehbigdeli/orgs",
"repos_url": "https://api.github.com/users/Salehbigdeli/repos",
"events_url": "https://api.github.com/users/Salehbigdeli/events{/privacy}",
"received_events_url": "https://api.github.com/users/Salehbigdeli/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-17T01:30:37 | 2022-11-05T12:23:53 | 2022-11-05T12:23:53 | NONE | null | Fixes: #5105
I think removing the directory with warning is a better solution for this issue. Because if we decide to keep existing files in directory, then we should deal with the case providing same directory for several datasets! Which we know is not possible since `dataset_info.json` exists in that directory. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5122/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5122/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5122",
"html_url": "https://github.com/huggingface/datasets/pull/5122",
"diff_url": "https://github.com/huggingface/datasets/pull/5122.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5122.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5121 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5121/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5121/comments | https://api.github.com/repos/huggingface/datasets/issues/5121/events | https://github.com/huggingface/datasets/pull/5121 | 1,410,681,067 | PR_kwDODunzps5A4gUB | 5,121 | Bugfix ignore function when creating new_fingerprint for caching | {
"login": "Salehbigdeli",
"id": 34204311,
"node_id": "MDQ6VXNlcjM0MjA0MzEx",
"avatar_url": "https://avatars.githubusercontent.com/u/34204311?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Salehbigdeli",
"html_url": "https://github.com/Salehbigdeli",
"followers_url": "https://api.github.com/users/Salehbigdeli/followers",
"following_url": "https://api.github.com/users/Salehbigdeli/following{/other_user}",
"gists_url": "https://api.github.com/users/Salehbigdeli/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Salehbigdeli/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Salehbigdeli/subscriptions",
"organizations_url": "https://api.github.com/users/Salehbigdeli/orgs",
"repos_url": "https://api.github.com/users/Salehbigdeli/repos",
"events_url": "https://api.github.com/users/Salehbigdeli/events{/privacy}",
"received_events_url": "https://api.github.com/users/Salehbigdeli/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-17T00:03:43 | 2022-10-17T12:39:36 | 2022-10-17T12:39:36 | NONE | null | maybe fixes: #5109 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5121/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5121/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5121",
"html_url": "https://github.com/huggingface/datasets/pull/5121",
"diff_url": "https://github.com/huggingface/datasets/pull/5121.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5121.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5120 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5120/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5120/comments | https://api.github.com/repos/huggingface/datasets/issues/5120/events | https://github.com/huggingface/datasets/pull/5120 | 1,410,641,221 | PR_kwDODunzps5A4X10 | 5,120 | Fix `tqdm` zip bug | {
"login": "david1542",
"id": 9879252,
"node_id": "MDQ6VXNlcjk4NzkyNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9879252?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/david1542",
"html_url": "https://github.com/david1542",
"followers_url": "https://api.github.com/users/david1542/followers",
"following_url": "https://api.github.com/users/david1542/following{/other_user}",
"gists_url": "https://api.github.com/users/david1542/gists{/gist_id}",
"starred_url": "https://api.github.com/users/david1542/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david1542/subscriptions",
"organizations_url": "https://api.github.com/users/david1542/orgs",
"repos_url": "https://api.github.com/users/david1542/repos",
"events_url": "https://api.github.com/users/david1542/events{/privacy}",
"received_events_url": "https://api.github.com/users/david1542/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-16T22:19:18 | 2022-10-23T10:27:53 | 2022-10-19T08:53:17 | CONTRIBUTOR | null | This PR solves #5117, by wrapping the entire `zip` clause in tqdm.
For more information, please checkout this Stack Overflow thread:
https://stackoverflow.com/questions/41171191/tqdm-progressbar-and-zip-built-in-do-not-work-together | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5120/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5120/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5120",
"html_url": "https://github.com/huggingface/datasets/pull/5120",
"diff_url": "https://github.com/huggingface/datasets/pull/5120.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5120.patch",
"merged_at": "2022-10-19T08:53:17"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5119 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5119/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5119/comments | https://api.github.com/repos/huggingface/datasets/issues/5119/events | https://github.com/huggingface/datasets/pull/5119 | 1,410,561,363 | PR_kwDODunzps5A4IQp | 5,119 | [TYPO] Update new_dataset_script.py | {
"login": "cakiki",
"id": 3664563,
"node_id": "MDQ6VXNlcjM2NjQ1NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cakiki",
"html_url": "https://github.com/cakiki",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://api.github.com/users/cakiki/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cakiki/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cakiki/subscriptions",
"organizations_url": "https://api.github.com/users/cakiki/orgs",
"repos_url": "https://api.github.com/users/cakiki/repos",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"received_events_url": "https://api.github.com/users/cakiki/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-16T17:36:49 | 2022-10-19T09:48:19 | 2022-10-19T09:45:59 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5119/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5119/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5119",
"html_url": "https://github.com/huggingface/datasets/pull/5119",
"diff_url": "https://github.com/huggingface/datasets/pull/5119.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5119.patch",
"merged_at": "2022-10-19T09:45:59"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5118 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5118/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5118/comments | https://api.github.com/repos/huggingface/datasets/issues/5118/events | https://github.com/huggingface/datasets/issues/5118 | 1,410,547,373 | I_kwDODunzps5UEz6t | 5,118 | Installing `datasets` on M1 computers | {
"login": "david1542",
"id": 9879252,
"node_id": "MDQ6VXNlcjk4NzkyNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9879252?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/david1542",
"html_url": "https://github.com/david1542",
"followers_url": "https://api.github.com/users/david1542/followers",
"following_url": "https://api.github.com/users/david1542/following{/other_user}",
"gists_url": "https://api.github.com/users/david1542/gists{/gist_id}",
"starred_url": "https://api.github.com/users/david1542/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david1542/subscriptions",
"organizations_url": "https://api.github.com/users/david1542/orgs",
"repos_url": "https://api.github.com/users/david1542/repos",
"events_url": "https://api.github.com/users/david1542/events{/privacy}",
"received_events_url": "https://api.github.com/users/david1542/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Thanks for reporting, @david1542."
] | 2022-10-16T16:50:08 | 2022-10-19T09:10:08 | 2022-10-19T09:10:08 | CONTRIBUTOR | null | ## Describe the bug
I wanted to install `datasets` dependencies on my M1 (in order to start contributing to the project). However, I got an error regarding `tensorflow`.
On M1, `tensorflow-macos` needs to be installed instead. Can we add a conditional requirement, so that `tensorflow-macos` would be installed on M1?
## Steps to reproduce the bug
Fresh clone this project (on m1), create a virtualenv and run this:
```python
pip install -e ".[dev]"
```
## Expected results
Installation should be smooth, and all the dependencies should be installed on M1.
## Actual results
You should receive an error, saying pip couldn't find a version that matches this pattern:
```
tensorflow>=2.3,!=2.6.0,!=2.6.1
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.6.2.dev0
- Platform: macOS-12.6-arm64-arm-64bit
- Python version: 3.9.6
- PyArrow version: 7.0.0
- Pandas version: 1.5.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5118/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5118/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5117 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5117/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5117/comments | https://api.github.com/repos/huggingface/datasets/issues/5117/events | https://github.com/huggingface/datasets/issues/5117 | 1,409,571,346 | I_kwDODunzps5UBFoS | 5,117 | Progress bars have color red and never completed to 100% | {
"login": "echatzikyriakidis",
"id": 63857529,
"node_id": "MDQ6VXNlcjYzODU3NTI5",
"avatar_url": "https://avatars.githubusercontent.com/u/63857529?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/echatzikyriakidis",
"html_url": "https://github.com/echatzikyriakidis",
"followers_url": "https://api.github.com/users/echatzikyriakidis/followers",
"following_url": "https://api.github.com/users/echatzikyriakidis/following{/other_user}",
"gists_url": "https://api.github.com/users/echatzikyriakidis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/echatzikyriakidis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/echatzikyriakidis/subscriptions",
"organizations_url": "https://api.github.com/users/echatzikyriakidis/orgs",
"repos_url": "https://api.github.com/users/echatzikyriakidis/repos",
"events_url": "https://api.github.com/users/echatzikyriakidis/events{/privacy}",
"received_events_url": "https://api.github.com/users/echatzikyriakidis/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "david1542",
"id": 9879252,
"node_id": "MDQ6VXNlcjk4NzkyNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9879252?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/david1542",
"html_url": "https://github.com/david1542",
"followers_url": "https://api.github.com/users/david1542/followers",
"following_url": "https://api.github.com/users/david1542/following{/other_user}",
"gists_url": "https://api.github.com/users/david1542/gists{/gist_id}",
"starred_url": "https://api.github.com/users/david1542/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david1542/subscriptions",
"organizations_url": "https://api.github.com/users/david1542/orgs",
"repos_url": "https://api.github.com/users/david1542/repos",
"events_url": "https://api.github.com/users/david1542/events{/privacy}",
"received_events_url": "https://api.github.com/users/david1542/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "david1542",
"id": 9879252,
"node_id": "MDQ6VXNlcjk4NzkyNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9879252?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/david1542",
"html_url": "https://github.com/david1542",
"followers_url": "https://api... | null | [
"Hi @echatzikyriakidis, thanks for submitting the issue.\r\nWhich shell are you using exactly? I tried to run the command you sent, but I don't see colors at all 🧐\r\n\r\nI tried from bash and zsh as well.",
"Hi @david1542 ,\r\n\r\nI use Google Colab.\r\n",
"Got it. I [created a PR](https://github.com/huggingf... | 2022-10-14T16:12:30 | 2022-10-23T12:58:41 | 2022-10-23T12:58:41 | NONE | null | ## Describe the bug
Progress bars after transformative operations turn in red and never be completed to 100%
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset('rotten_tomatoes', split='test').filter(lambda o: True)
```
## Expected results
Progress bar should be 100% and green
## Actual results
Progress bar turn in red and never completed to 100%
## Environment info
- `datasets` version: 2.6.1
- Platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.14
- PyArrow version: 6.0.1
- Pandas version: 1.3.5 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5117/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5117/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5116 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5116/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5116/comments | https://api.github.com/repos/huggingface/datasets/issues/5116/events | https://github.com/huggingface/datasets/pull/5116 | 1,409,549,471 | PR_kwDODunzps5A09sk | 5,116 | Use yaml for issue templates + revamp | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-14T15:53:13 | 2022-10-19T13:05:49 | 2022-10-19T13:03:22 | CONTRIBUTOR | null | Use YAML instead of markdown (more expressive) for the issue templates. In addition, update their structure/fields to be more aligned with Transformers.
PS: also removes the "add_dataset" PR template, as we no longer accept such PRs. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5116/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5116/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5116",
"html_url": "https://github.com/huggingface/datasets/pull/5116",
"diff_url": "https://github.com/huggingface/datasets/pull/5116.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5116.patch",
"merged_at": "2022-10-19T13:03:22"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5115 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5115/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5115/comments | https://api.github.com/repos/huggingface/datasets/issues/5115/events | https://github.com/huggingface/datasets/pull/5115 | 1,409,250,020 | PR_kwDODunzps5Az9Pm | 5,115 | Fix iter_batches | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-14T12:06:14 | 2022-10-14T15:02:15 | 2022-10-14T14:59:58 | MEMBER | null | The `pa.Table.to_reader()` method available in `pyarrow>=8.0.0` may return chunks of size < `max_chunksize`, therefore `iter_batches` can return batches smaller than the `batch_size` specified by the user
Therefore batched `map` couldn't always use batches of the right size, e.g. this fails because it runs only on one batch of one element:
```python
from datasets import Dataset, concatenate_datasets
ds = concatenate_datasets([Dataset.from_dict({"a": [i]}) for i in range(10)])
ds2 = ds.map(lambda _: {}, batched=True)
assert list(ds2) == list(ds)
```
This was introduced in https://github.com/huggingface/datasets/pull/5030
Close https://github.com/huggingface/datasets/issues/5111
This will require a patch release along with https://github.com/huggingface/datasets/pull/5113
TODO:
- [x] fix tests
- [x] add more tests | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5115/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5115/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5115",
"html_url": "https://github.com/huggingface/datasets/pull/5115",
"diff_url": "https://github.com/huggingface/datasets/pull/5115.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5115.patch",
"merged_at": "2022-10-14T14:59:58"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5113 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5113/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5113/comments | https://api.github.com/repos/huggingface/datasets/issues/5113/events | https://github.com/huggingface/datasets/pull/5113 | 1,409,207,607 | PR_kwDODunzps5Az0Ei | 5,113 | Fix filter indices when batched | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-14T11:30:03 | 2022-10-24T06:21:09 | 2022-10-14T12:11:44 | MEMBER | null | This PR fixes a bug introduced by:
- #5030
Fix #5112. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5113/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5113/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5113",
"html_url": "https://github.com/huggingface/datasets/pull/5113",
"diff_url": "https://github.com/huggingface/datasets/pull/5113.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5113.patch",
"merged_at": "2022-10-14T12:11:44"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5112 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5112/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5112/comments | https://api.github.com/repos/huggingface/datasets/issues/5112/events | https://github.com/huggingface/datasets/issues/5112 | 1,409,143,409 | I_kwDODunzps5T_dJx | 5,112 | Bug with filtered indices | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"The issue is here:\r\nhttps://github.com/huggingface/datasets/blob/3ad9644b9a2e4558dd1d0f1e43c67658674e6228/src/datasets/arrow_dataset.py#L2964",
"@PartiallyTyped, @Muennighoff: the issue is fixed.\r\n\r\nWe are planning to make a patch release today.",
"Thanks a lot for the swift response! For a brief moment ... | 2022-10-14T10:35:47 | 2022-10-14T13:55:03 | 2022-10-14T12:11:45 | MEMBER | null | ## Describe the bug
As reported by @PartiallyTyped (and by @Muennighoff):
- https://github.com/huggingface/datasets/issues/5111#issuecomment-1278652524
There is an issue with the indices of a filtered dataset.
## Steps to reproduce the bug
```python
ds = Dataset.from_dict({"num": [0, 1, 2, 3]})
ds = ds.filter(lambda num: num % 2 == 0, input_columns="num", batch_size=2)
assert all(item["num"] % 2 == 0 for item in ds)
```
## Expected results
The indices of the filtered dataset should correspond to the examples with "language" equals to "english".
## Actual results
Indices to items with other languages are included in the filtered dataset indices
## Preliminar investigation
It seems a bug introduced by:
- #5030
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5112/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5112/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5111 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5111/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5111/comments | https://api.github.com/repos/huggingface/datasets/issues/5111/events | https://github.com/huggingface/datasets/issues/5111 | 1,408,143,170 | I_kwDODunzps5T7o9C | 5,111 | map and filter not working properly in multiprocessing with the new release 2.6.0 | {
"login": "loubnabnl",
"id": 44069155,
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loubnabnl",
"html_url": "https://github.com/loubnabnl",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "https://api.github.com/users/loubnabnl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loubnabnl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loubnabnl/subscriptions",
"organizations_url": "https://api.github.com/users/loubnabnl/orgs",
"repos_url": "https://api.github.com/users/loubnabnl/repos",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"received_events_url": "https://api.github.com/users/loubnabnl/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"Same bug exists with `num_proc=1` on colab. `3.7.14 (default, Sep 8 2022, 00:06:44) [GCC 7.5.0]` ",
"Thanks for reporting, @loubnabnl and for the additional information, @PartiallyTyped.\r\n\r\nHowever, I'm not able to reproduce this issue, neither locally nor on Colab:\r\n```\r\nDataset({\r\n features: ['re... | 2022-10-13T17:00:55 | 2022-10-17T08:26:59 | 2022-10-14T14:59:59 | NONE | null | ## Describe the bug
When mapping is used on a dataset with more than one process, there is a weird behavior when trying to use `filter` , it's like only the samples from one worker are retrieved, one needs to specify the same `num_proc` in filter for it to work properly. This doesn't happen with `datasets` version 2.5.2
In the code below the data is filtered differently when we increase `num_proc` used in `map` although the datsets before and after mapping have identical elements.
## Steps to reproduce the bug
```python
import datasets
from datasets import load_dataset
def preprocess(example):
return example
ds = load_dataset("codeparrot/codeparrot-clean-valid", split="train").select([i for i in range(10)])
ds1 = ds.map(preprocess, num_proc=2)
ds2 = ds.map(preprocess)
# the datasets elements are the same
for i in range(len(ds1)):
assert ds1[i]==ds2[i]
print(f'Target column before filtering {ds1["autogenerated"]}')
print(f'Target column before filtering {ds2["autogenerated"]}')
print(f"datasets version {datasets.__version__}")
ds_filtered_1 = ds1.filter(lambda x: not x["autogenerated"])
ds_filtered_2 = ds2.filter(lambda x: not x["autogenerated"])
# all elements in Target column are false so they should all be kept, but for ds2 only the first 5=num_samples/num_proc are kept
print(ds_filtered_1)
print(ds_filtered_2)
```
```
Target column before filtering [False, False, False, False, False, False, False, False, False, False]
Target column before filtering [False, False, False, False, False, False, False, False, False, False]
Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],
num_rows: 5
})
Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],
num_rows: 10
})
```
## Expected results
Increasing `num_proc` in mapping shouldn't alter filtering. With the previous version 2.5.2 this doesn't happen
## Actual results
Filtering doesn't work properly when we increase `num_proc` in mapping but not when calling `filter`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.6.0
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.13
- PyArrow version: 8.0.0
- Pandas version: 1.4.2 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5111/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5111/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5109 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5109/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5109/comments | https://api.github.com/repos/huggingface/datasets/issues/5109/events | https://github.com/huggingface/datasets/issues/5109 | 1,407,434,706 | I_kwDODunzps5T47_S | 5,109 | Map caching not working for some class methods | {
"login": "Mouhanedg56",
"id": 23029765,
"node_id": "MDQ6VXNlcjIzMDI5NzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/23029765?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mouhanedg56",
"html_url": "https://github.com/Mouhanedg56",
"followers_url": "https://api.github.com/users/Mouhanedg56/followers",
"following_url": "https://api.github.com/users/Mouhanedg56/following{/other_user}",
"gists_url": "https://api.github.com/users/Mouhanedg56/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mouhanedg56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mouhanedg56/subscriptions",
"organizations_url": "https://api.github.com/users/Mouhanedg56/orgs",
"repos_url": "https://api.github.com/users/Mouhanedg56/repos",
"events_url": "https://api.github.com/users/Mouhanedg56/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mouhanedg56/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"The hash used for caching is computed by pickling recursively the function passed to `map`. Maybe some objects don't have the same hash across sessions. In particular you can check the hash of your model using\r\n```python\r\nfrom datasets.fingerprint import Hasher\r\nobj = AutoModel.from_config(config=config, ad... | 2022-10-13T09:12:58 | 2022-10-17T10:38:45 | 2022-10-17T10:38:45 | CONTRIBUTOR | null | ## Describe the bug
The cache loading is not working as expected for some class methods with a model stored in an attribute.
The new fingerprint for `_map_single` is not the same at each run. The hasher generate a different hash for the class method.
This comes from `dumps` function in `datasets.utils.py_utils` which generates a different dump at each run.
## Steps to reproduce the bug
```python
from datasets import load_dataset
from transformers import AutoConfig, AutoModel, AutoTokenizer
dataset = load_dataset("ethos", "binary")
BASE_MODELNAME = "sentence-transformers/all-MiniLM-L6-v2"
class Object:
def __init__(self):
config = AutoConfig.from_pretrained(BASE_MODELNAME)
self.bert = AutoModel.from_config(config=config, add_pooling_layer=False)
self.tok = AutoTokenizer.from_pretrained(BASE_MODELNAME)
def tokenize(self, examples):
tokenized_texts = self.tok(
examples["text"],
padding="max_length",
truncation=True,
max_length=256,
)
return tokenized_texts
instance = Object()
result = dict()
for phase in ["train"]:
result[phase] = dataset[phase].map(instance.tokenize, batched=True, load_from_cache_file=True, num_proc=2)
```
## Expected results
Load cache instead of recompute result.
## Actual results
Result recomputed from scratch at each run.
The cache works fine when deleting `bert` attribute.
## Environment info
- `datasets` version: 2.5.3.dev0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.13
- PyArrow version: 7.0.0
- Pandas version: 1.5.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5109/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5109/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5108 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5108/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5108/comments | https://api.github.com/repos/huggingface/datasets/issues/5108/events | https://github.com/huggingface/datasets/pull/5108 | 1,407,044,107 | PR_kwDODunzps5AskeK | 5,108 | Fix a typo in arrow_dataset.py | {
"login": "yangky11",
"id": 5431913,
"node_id": "MDQ6VXNlcjU0MzE5MTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5431913?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yangky11",
"html_url": "https://github.com/yangky11",
"followers_url": "https://api.github.com/users/yangky11/followers",
"following_url": "https://api.github.com/users/yangky11/following{/other_user}",
"gists_url": "https://api.github.com/users/yangky11/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yangky11/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yangky11/subscriptions",
"organizations_url": "https://api.github.com/users/yangky11/orgs",
"repos_url": "https://api.github.com/users/yangky11/repos",
"events_url": "https://api.github.com/users/yangky11/events{/privacy}",
"received_events_url": "https://api.github.com/users/yangky11/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-13T02:33:55 | 2022-10-14T09:47:28 | 2022-10-14T09:47:27 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5108/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5108/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5108",
"html_url": "https://github.com/huggingface/datasets/pull/5108",
"diff_url": "https://github.com/huggingface/datasets/pull/5108.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5108.patch",
"merged_at": "2022-10-14T09:47:27"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5107 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5107/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5107/comments | https://api.github.com/repos/huggingface/datasets/issues/5107/events | https://github.com/huggingface/datasets/pull/5107 | 1,406,736,710 | PR_kwDODunzps5ArjCZ | 5,107 | Multiprocessed dataset builder | {
"login": "TevenLeScao",
"id": 26709476,
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TevenLeScao",
"html_url": "https://github.com/TevenLeScao",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_url": "https://api.github.com/users/TevenLeScao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TevenLeScao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TevenLeScao/subscriptions",
"organizations_url": "https://api.github.com/users/TevenLeScao/orgs",
"repos_url": "https://api.github.com/users/TevenLeScao/repos",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"received_events_url": "https://api.github.com/users/TevenLeScao/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-12T19:59:17 | 2022-12-01T15:37:09 | 2022-11-09T17:11:43 | MEMBER | null | This PR adds the multiprocessing part of #2650 (but not the caching of already-computed arrow files). On the other side, loading of sharded arrow files still needs to be implemented (sharded parquet files can already be loaded). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5107/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5107/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5107",
"html_url": "https://github.com/huggingface/datasets/pull/5107",
"diff_url": "https://github.com/huggingface/datasets/pull/5107.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5107.patch",
"merged_at": "2022-11-09T17:11:43"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5106 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5106/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5106/comments | https://api.github.com/repos/huggingface/datasets/issues/5106/events | https://github.com/huggingface/datasets/pull/5106 | 1,406,635,758 | PR_kwDODunzps5ArM6G | 5,106 | Fix task template reload from dict | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-12T18:33:49 | 2022-10-13T09:59:07 | 2022-10-13T09:56:51 | MEMBER | null | Since #4926 the JSON dumps are simplified and it made task template dicts empty by default.
I fixed this by always including the task name which is needed to reload a task from a dict | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5106/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5106/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5106",
"html_url": "https://github.com/huggingface/datasets/pull/5106",
"diff_url": "https://github.com/huggingface/datasets/pull/5106.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5106.patch",
"merged_at": "2022-10-13T09:56:51"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5104 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5104/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5104/comments | https://api.github.com/repos/huggingface/datasets/issues/5104/events | https://github.com/huggingface/datasets/pull/5104 | 1,405,973,102 | PR_kwDODunzps5Ao9Mq | 5,104 | Fix loading how to guide (#5102) | {
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-12T10:34:42 | 2022-10-12T11:34:07 | 2022-10-12T11:31:55 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5104/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5104/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5104",
"html_url": "https://github.com/huggingface/datasets/pull/5104",
"diff_url": "https://github.com/huggingface/datasets/pull/5104.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5104.patch",
"merged_at": "2022-10-12T11:31:55"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5103 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5103/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5103/comments | https://api.github.com/repos/huggingface/datasets/issues/5103/events | https://github.com/huggingface/datasets/pull/5103 | 1,405,956,311 | PR_kwDODunzps5Ao5gI | 5,103 | url encode hub url (#5099) | {
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-12T10:22:12 | 2022-10-12T15:27:24 | 2022-10-12T15:24:47 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5103/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5103/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5103",
"html_url": "https://github.com/huggingface/datasets/pull/5103",
"diff_url": "https://github.com/huggingface/datasets/pull/5103.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5103.patch",
"merged_at": "2022-10-12T15:24:47"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5102 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5102/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5102/comments | https://api.github.com/repos/huggingface/datasets/issues/5102/events | https://github.com/huggingface/datasets/issues/5102 | 1,404,746,554 | I_kwDODunzps5Turs6 | 5,102 | Error in create a dataset from a Python generator | {
"login": "yangxuhui",
"id": 9004682,
"node_id": "MDQ6VXNlcjkwMDQ2ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9004682?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yangxuhui",
"html_url": "https://github.com/yangxuhui",
"followers_url": "https://api.github.com/users/yangxuhui/followers",
"following_url": "https://api.github.com/users/yangxuhui/following{/other_user}",
"gists_url": "https://api.github.com/users/yangxuhui/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yangxuhui/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yangxuhui/subscriptions",
"organizations_url": "https://api.github.com/users/yangxuhui/orgs",
"repos_url": "https://api.github.com/users/yangxuhui/repos",
"events_url": "https://api.github.com/users/yangxuhui/events{/privacy}",
"received_events_url": "https://api.github.com/users/yangxuhui/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODk... | closed | false | {
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": ... | null | [
"Hi, thanks for reporting! The last line should be `dataset = Dataset.from_generator(my_gen)`.",
"Can I work on this one?"
] | 2022-10-11T14:28:58 | 2022-10-12T11:31:56 | 2022-10-12T11:31:56 | NONE | null | ## Describe the bug
In HOW-TO-GUIDES > Load > [Python generator](https://huggingface.co/docs/datasets/v2.5.2/en/loading#python-generator), the code example defines the `my_gen` function, but when creating the dataset, an undefined `my_dict` is passed in.
```Python
>>> from datasets import Dataset
>>> def my_gen():
... for i in range(1, 4):
... yield {"a": i}
>>> dataset = Dataset.from_generator(my_dict)
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5102/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5102/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5101 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5101/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5101/comments | https://api.github.com/repos/huggingface/datasets/issues/5101/events | https://github.com/huggingface/datasets/pull/5101 | 1,404,513,085 | PR_kwDODunzps5AkHJc | 5,101 | Free the "hf" filesystem protocol for `hffs` | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-11T11:57:21 | 2022-10-12T15:32:59 | 2022-10-12T15:30:38 | MEMBER | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5101/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5101/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5101",
"html_url": "https://github.com/huggingface/datasets/pull/5101",
"diff_url": "https://github.com/huggingface/datasets/pull/5101.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5101.patch",
"merged_at": "2022-10-12T15:30:38"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5100 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5100/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5100/comments | https://api.github.com/repos/huggingface/datasets/issues/5100/events | https://github.com/huggingface/datasets/issues/5100 | 1,404,458,586 | I_kwDODunzps5TtlZa | 5,100 | datasets[s3] sagemaker can't run a model - datasets issue with Value and ClassLabel and cast() method | {
"login": "jagochi",
"id": 115545475,
"node_id": "U_kgDOBuMVgw",
"avatar_url": "https://avatars.githubusercontent.com/u/115545475?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jagochi",
"html_url": "https://github.com/jagochi",
"followers_url": "https://api.github.com/users/jagochi/followers",
"following_url": "https://api.github.com/users/jagochi/following{/other_user}",
"gists_url": "https://api.github.com/users/jagochi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jagochi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jagochi/subscriptions",
"organizations_url": "https://api.github.com/users/jagochi/orgs",
"repos_url": "https://api.github.com/users/jagochi/repos",
"events_url": "https://api.github.com/users/jagochi/events{/privacy}",
"received_events_url": "https://api.github.com/users/jagochi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-11T11:16:31 | 2022-10-11T13:48:26 | 2022-10-11T13:48:26 | NONE | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5100/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5100/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5099 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5099/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5099/comments | https://api.github.com/repos/huggingface/datasets/issues/5099/events | https://github.com/huggingface/datasets/issues/5099 | 1,404,370,191 | I_kwDODunzps5TtP0P | 5,099 | datasets doesn't support # in data paths | {
"login": "loubnabnl",
"id": 44069155,
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loubnabnl",
"html_url": "https://github.com/loubnabnl",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "https://api.github.com/users/loubnabnl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loubnabnl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loubnabnl/subscriptions",
"organizations_url": "https://api.github.com/users/loubnabnl/orgs",
"repos_url": "https://api.github.com/users/loubnabnl/repos",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"received_events_url": "https://api.github.com/users/loubnabnl/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODk... | closed | false | {
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": ... | null | [
"`datasets` doesn't seem to urlencode the directory names here\r\n\r\nhttps://github.com/huggingface/datasets/blob/7feeb5648a63b6135a8259dedc3b1e19185ee4c7/src/datasets/utils/file_utils.py#L109-L111\r\n\r\nfor example we should have\r\n```python\r\nfrom datasets.utils.file_utils import hf_hub_url\r\n\r\nurl = hf_hu... | 2022-10-11T10:05:32 | 2022-10-13T13:14:20 | 2022-10-13T13:14:20 | NONE | null | ## Describe the bug
dataset files with `#` symbol their paths aren't read correctly.
## Steps to reproduce the bug
The data in folder `c#`of this [dataset](https://huggingface.co/datasets/loubnabnl/bigcode_csharp) can't be loaded. While the folder `c_sharp` with the same data is loaded properly
```python
ds = load_dataset('loubnabnl/bigcode_csharp', split="train", data_files=["data/c#/*"])
```
```
FileNotFoundError: Couldn't find file at https://huggingface.co/datasets/loubnabnl/bigcode_csharp/resolve/27a3166cff4bb18e11919cafa6f169c0f57483de/data/c#/data_0003.jsonl
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.2
- Platform: macOS-12.2.1-arm64-arm-64bit
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
cc @lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5099/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5098 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5098/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5098/comments | https://api.github.com/repos/huggingface/datasets/issues/5098/events | https://github.com/huggingface/datasets/issues/5098 | 1,404,058,518 | I_kwDODunzps5TsDuW | 5,098 | Classes label error when loading symbolic links using imagefolder | {
"login": "horizon86",
"id": 49552732,
"node_id": "MDQ6VXNlcjQ5NTUyNzMy",
"avatar_url": "https://avatars.githubusercontent.com/u/49552732?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/horizon86",
"html_url": "https://github.com/horizon86",
"followers_url": "https://api.github.com/users/horizon86/followers",
"following_url": "https://api.github.com/users/horizon86/following{/other_user}",
"gists_url": "https://api.github.com/users/horizon86/gists{/gist_id}",
"starred_url": "https://api.github.com/users/horizon86/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/horizon86/subscriptions",
"organizations_url": "https://api.github.com/users/horizon86/orgs",
"repos_url": "https://api.github.com/users/horizon86/repos",
"events_url": "https://api.github.com/users/horizon86/events{/privacy}",
"received_events_url": "https://api.github.com/users/horizon86/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | closed | false | {
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": ... | null | [
"It can be solved temporarily by remove `resolve` in \r\nhttps://github.com/huggingface/datasets/blob/bef23be3d9543b1ca2da87ab2f05070201044ddc/src/datasets/data_files.py#L278",
"Hi, thanks for reporting and suggesting a fix! We still need to account for `.`/`..` in the file path, so a more robust fix would be `P... | 2022-10-11T06:10:58 | 2022-11-14T14:40:20 | 2022-11-14T14:40:20 | NONE | null | **Is your feature request related to a problem? Please describe.**
Like this: #4015
When there are **symbolic links** to pictures in the data folder, the parent folder name of the **real file** will be used as the class name instead of the parent folder of the symbolic link itself. Can you give an option to decide whether to enable symbolic link tracking?
This is inconsistent with the `torchvision.datasets.ImageFolder` behavior.
For example:
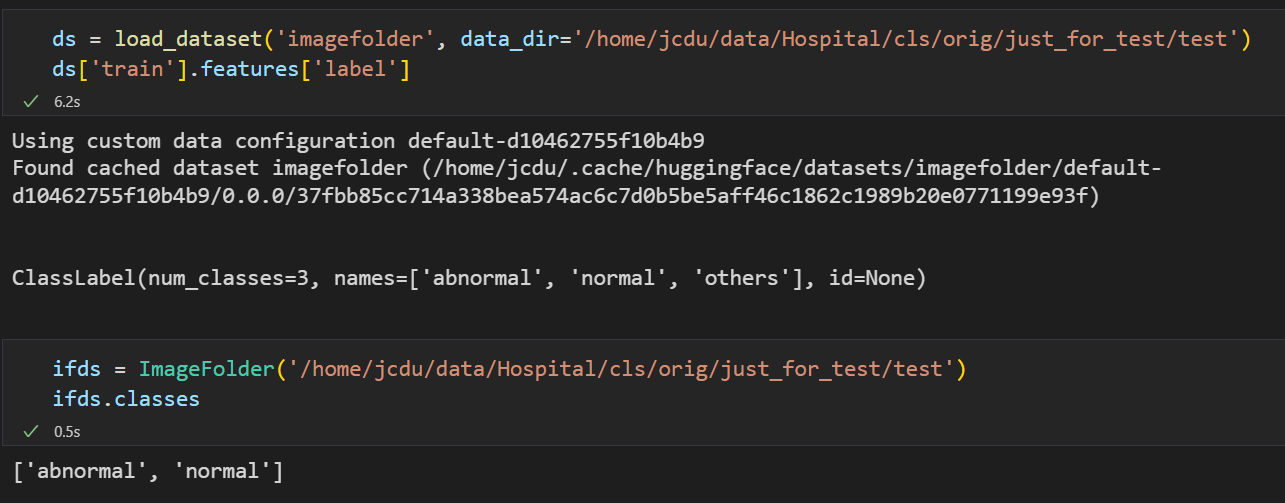

It use `others` in green circle as class label but not `abnormal`, I wish `load_dataset` not use the real file parent as label.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context about the feature request here.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5098/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5098/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5097 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5097/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5097/comments | https://api.github.com/repos/huggingface/datasets/issues/5097/events | https://github.com/huggingface/datasets/issues/5097 | 1,403,679,353 | I_kwDODunzps5TqnJ5 | 5,097 | Fatal error with pyarrow/libarrow.so | {
"login": "catalys1",
"id": 11340846,
"node_id": "MDQ6VXNlcjExMzQwODQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/11340846?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/catalys1",
"html_url": "https://github.com/catalys1",
"followers_url": "https://api.github.com/users/catalys1/followers",
"following_url": "https://api.github.com/users/catalys1/following{/other_user}",
"gists_url": "https://api.github.com/users/catalys1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/catalys1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/catalys1/subscriptions",
"organizations_url": "https://api.github.com/users/catalys1/orgs",
"repos_url": "https://api.github.com/users/catalys1/repos",
"events_url": "https://api.github.com/users/catalys1/events{/privacy}",
"received_events_url": "https://api.github.com/users/catalys1/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Thanks for reporting, @catalys1.\r\n\r\nThis seems a duplicate of:\r\n- #3310 \r\n\r\nThe source of the problem is in PyArrow:\r\n- [ARROW-15141: [C++] Fatal error condition occurred in aws_thread_launch](https://issues.apache.org/jira/browse/ARROW-15141)\r\n- [ARROW-17501: [C++] Fatal error condition occurred in ... | 2022-10-10T20:29:04 | 2022-10-11T06:56:01 | 2022-10-11T06:56:00 | NONE | null | ## Describe the bug
When using datasets, at the very end of my jobs the program crashes (see trace below).
It doesn't seem to affect anything, as it appears to happen as the program is closing down. Just importing `datasets` is enough to cause the error.
## Steps to reproduce the bug
This is sufficient to reproduce the problem:
```bash
python -c "import datasets"
```
## Expected results
Program should run to completion without an error.
## Actual results
```bash
Fatal error condition occurred in /opt/vcpkg/buildtrees/aws-c-io/src/9e6648842a-364b708815.clean/source/event_loop.c:72: aws_thread_launch(&cleanup_thread, s_event_loop_destroy_async_thread_fn, el_group, &thread_options) == AWS_OP_SUCCESS
Exiting Application
################################################################################
Stack trace:
################################################################################
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x200af06) [0x150dff547f06]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x20028e5) [0x150dff53f8e5]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x1f27e09) [0x150dff464e09]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x200ba3d) [0x150dff548a3d]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x1f25948) [0x150dff462948]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x200ba3d) [0x150dff548a3d]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x1ee0b46) [0x150dff41db46]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x194546a) [0x150dfee8246a]
/lib64/libc.so.6(+0x39b0c) [0x150e15eadb0c]
/lib64/libc.so.6(on_exit+0) [0x150e15eadc40]
/u/user/miniconda3/envs/env/bin/python(+0x28db18) [0x560ae370eb18]
/u/user/miniconda3/envs/env/bin/python(+0x28db4b) [0x560ae370eb4b]
/u/user/miniconda3/envs/env/bin/python(+0x28db90) [0x560ae370eb90]
/u/user/miniconda3/envs/env/bin/python(_PyRun_SimpleFileObject+0x1e6) [0x560ae37123e6]
/u/user/miniconda3/envs/env/bin/python(_PyRun_AnyFileObject+0x44) [0x560ae37124c4]
/u/user/miniconda3/envs/env/bin/python(Py_RunMain+0x35d) [0x560ae37135bd]
/u/user/miniconda3/envs/env/bin/python(Py_BytesMain+0x39) [0x560ae37137d9]
/lib64/libc.so.6(__libc_start_main+0xf3) [0x150e15e97493]
/u/user/miniconda3/envs/env/bin/python(+0x2125d4) [0x560ae36935d4]
Aborted (core dumped)
```
## Environment info
- `datasets` version: 2.5.1
- Platform: Linux-4.18.0-348.23.1.el8_5.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.4
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5097/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5097/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5095 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5095/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5095/comments | https://api.github.com/repos/huggingface/datasets/issues/5095/events | https://github.com/huggingface/datasets/pull/5095 | 1,403,221,408 | PR_kwDODunzps5Afzsq | 5,095 | Fix tutorial (#5093) | {
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-10T13:55:15 | 2022-10-10T17:50:52 | 2022-10-10T15:32:20 | CONTRIBUTOR | null | Close #5093 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5095/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5095/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5095",
"html_url": "https://github.com/huggingface/datasets/pull/5095",
"diff_url": "https://github.com/huggingface/datasets/pull/5095.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5095.patch",
"merged_at": "2022-10-10T15:32:20"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5093 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5093/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5093/comments | https://api.github.com/repos/huggingface/datasets/issues/5093/events | https://github.com/huggingface/datasets/issues/5093 | 1,402,939,660 | I_kwDODunzps5TnykM | 5,093 | Mismatch between tutoriel and doc | {
"login": "clefourrier",
"id": 22726840,
"node_id": "MDQ6VXNlcjIyNzI2ODQw",
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clefourrier",
"html_url": "https://github.com/clefourrier",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_url": "https://api.github.com/users/clefourrier/gists{/gist_id}",
"starred_url": "https://api.github.com/users/clefourrier/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/clefourrier/subscriptions",
"organizations_url": "https://api.github.com/users/clefourrier/orgs",
"repos_url": "https://api.github.com/users/clefourrier/repos",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"received_events_url": "https://api.github.com/users/clefourrier/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODk... | closed | false | {
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": ... | null | [
"Hi, thanks for reporting! This line should be replaced with \r\n```python\r\ndataset = dataset.map(lambda examples: tokenizer(examples[\"text\"], return_tensors=\"np\"), batched=True)\r\n```\r\nfor it to work (the `return_tensors` part inside the `tokenizer` call).",
"Can I work on this?",
"Fixed in https://gi... | 2022-10-10T10:23:53 | 2022-10-10T17:51:15 | 2022-10-10T17:51:14 | CONTRIBUTOR | null | ## Describe the bug
In the "Process text data" tutorial, [`map` has `return_tensors` as kwarg](https://huggingface.co/docs/datasets/main/en/nlp_process#map). It does not seem to appear in the [function documentation](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.map), nor to work.
## Steps to reproduce the bug
MWE:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
from datasets import load_dataset
dataset = load_dataset("lhoestq/demo1", split="train")
dataset = dataset.map(lambda examples: tokenizer(examples["review"]), batched=True, return_tensors="pt")
```
## Expected results
return_tensors to be a valid kwarg :smiley:
## Actual results
```python
>> TypeError: map() got an unexpected keyword argument 'return_tensors'
```
## Environment info
- `datasets` version: 2.3.2
- Platform: Linux-5.14.0-1052-oem-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5093/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5093/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5092 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5092/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5092/comments | https://api.github.com/repos/huggingface/datasets/issues/5092/events | https://github.com/huggingface/datasets/pull/5092 | 1,402,713,517 | PR_kwDODunzps5AeIsS | 5,092 | Use HTML relative paths for tiles in the docs | {
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-10T07:24:27 | 2022-10-11T13:25:45 | 2022-10-11T13:23:23 | MEMBER | null | This PR replaces the absolute paths in the landing page tiles with relative ones so that one can test navigation both locally in and in future PRs (see [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5084/en/index) for an example PR where the links don't work).
I encountered this while working on the `optimum` docs and figured I'd fix it elsewhere too :)
Internal Slack thread: https://huggingface.slack.com/archives/C02GLJ5S0E9/p1665129710176619 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5092/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5092/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5092",
"html_url": "https://github.com/huggingface/datasets/pull/5092",
"diff_url": "https://github.com/huggingface/datasets/pull/5092.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5092.patch",
"merged_at": "2022-10-11T13:23:23"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5091 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5091/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5091/comments | https://api.github.com/repos/huggingface/datasets/issues/5091/events | https://github.com/huggingface/datasets/pull/5091 | 1,401,112,552 | PR_kwDODunzps5AZCm9 | 5,091 | Allow connection objects in `from_sql` + small doc improvement | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-07T12:39:44 | 2022-10-09T13:19:15 | 2022-10-09T13:16:57 | CONTRIBUTOR | null | Allow connection objects in `from_sql` (emit a warning that they are cachable) and add a tip that explains the format of the con parameter when provided as a URI string.
PS: ~~This PR contains a parameter link, so https://github.com/huggingface/doc-builder/pull/311 needs to be merged before it's "ready for review".~~ Done! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5091/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5091/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5091",
"html_url": "https://github.com/huggingface/datasets/pull/5091",
"diff_url": "https://github.com/huggingface/datasets/pull/5091.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5091.patch",
"merged_at": "2022-10-09T13:16:57"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5090 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5090/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5090/comments | https://api.github.com/repos/huggingface/datasets/issues/5090/events | https://github.com/huggingface/datasets/issues/5090 | 1,401,102,407 | I_kwDODunzps5TgyBH | 5,090 | Review sync issues from GitHub to Hub | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Nice!!"
] | 2022-10-07T12:31:56 | 2022-10-08T07:07:36 | 2022-10-08T07:07:36 | MEMBER | null | ## Describe the bug
We have discovered that sometimes there were sync issues between GitHub and Hub datasets, after a merge commit to main branch.
For example:
- this merge commit: https://github.com/huggingface/datasets/commit/d74a9e8e4bfff1fed03a4cab99180a841d7caf4b
- was not properly synced with the Hub: https://github.com/huggingface/datasets/actions/runs/3002495269/jobs/4819769684
```
[main 9e641de] Add Papers with Code ID to scifact dataset (#4941)
Author: Albert Villanova del Moral <albertvillanova@users.noreply.huggingface.co>
1 file changed, 42 insertions(+), 14 deletions(-)
push failed !
GitCommandError(['git', 'push'], 1, b'remote: ---------------------------------------------------------- \nremote: Sorry, your push was rejected during YAML metadata verification: \nremote: - Error: "license" does not match any of the allowed types \nremote: ---------------------------------------------------------- \nremote: Please find the documentation at: \nremote: https://huggingface.co/docs/hub/models-cards#model-card-metadata \nremote: ---------------------------------------------------------- \nTo [https://huggingface.co/datasets/scifact.git\n](https://huggingface.co/datasets/scifact.git/n) ! [remote rejected] main -> main (pre-receive hook declined)\nerror: failed to push some refs to \'[https://huggingface.co/datasets/scifact.git\](https://huggingface.co/datasets/scifact.git/)'', b'')
```
We are reviewing sync issues in previous commits to recover them and repushing to the Hub.
TODO: Review
- [x] #4941
- scifact
- [x] #4931
- scifact
- [x] #4753
- wikipedia
- [x] #4554
- wmt17, wmt19, wmt_t2t
- Fixed with "Release 2.4.0" commit: https://github.com/huggingface/datasets/commit/401d4c4f9b9594cb6527c599c0e7a72ce1a0ea49
- https://huggingface.co/datasets/wmt17/commit/5c0afa83fbbd3508ff7627c07f1b27756d1379ea
- https://huggingface.co/datasets/wmt19/commit/b8ad5bf1960208a376a0ab20bc8eac9638f7b400
- https://huggingface.co/datasets/wmt_t2t/commit/b6d67191804dd0933476fede36754a436b48d1fc
- [x] #4607
- [x] #4416
- lccc
- Fixed with "Release 2.3.0" commit: https://huggingface.co/datasets/lccc/commit/8b1f8cf425b5653a0a4357a53205aac82ce038d1
- [x] #4367
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5090/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5090/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5087 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5087/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5087/comments | https://api.github.com/repos/huggingface/datasets/issues/5087/events | https://github.com/huggingface/datasets/pull/5087 | 1,400,487,967 | PR_kwDODunzps5AW-N9 | 5,087 | Fix filter with empty indices | {
"login": "Mouhanedg56",
"id": 23029765,
"node_id": "MDQ6VXNlcjIzMDI5NzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/23029765?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mouhanedg56",
"html_url": "https://github.com/Mouhanedg56",
"followers_url": "https://api.github.com/users/Mouhanedg56/followers",
"following_url": "https://api.github.com/users/Mouhanedg56/following{/other_user}",
"gists_url": "https://api.github.com/users/Mouhanedg56/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mouhanedg56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mouhanedg56/subscriptions",
"organizations_url": "https://api.github.com/users/Mouhanedg56/orgs",
"repos_url": "https://api.github.com/users/Mouhanedg56/repos",
"events_url": "https://api.github.com/users/Mouhanedg56/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mouhanedg56/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-07T01:07:00 | 2022-10-07T18:43:03 | 2022-10-07T18:40:26 | CONTRIBUTOR | null | Fix #5085 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5087/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5087/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5087",
"html_url": "https://github.com/huggingface/datasets/pull/5087",
"diff_url": "https://github.com/huggingface/datasets/pull/5087.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5087.patch",
"merged_at": "2022-10-07T18:40:26"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5086 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5086/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5086/comments | https://api.github.com/repos/huggingface/datasets/issues/5086/events | https://github.com/huggingface/datasets/issues/5086 | 1,400,216,975 | I_kwDODunzps5TdZ2P | 5,086 | HTTPError: 404 Client Error: Not Found for url | {
"login": "km5ar",
"id": 54015474,
"node_id": "MDQ6VXNlcjU0MDE1NDc0",
"avatar_url": "https://avatars.githubusercontent.com/u/54015474?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/km5ar",
"html_url": "https://github.com/km5ar",
"followers_url": "https://api.github.com/users/km5ar/followers",
"following_url": "https://api.github.com/users/km5ar/following{/other_user}",
"gists_url": "https://api.github.com/users/km5ar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/km5ar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/km5ar/subscriptions",
"organizations_url": "https://api.github.com/users/km5ar/orgs",
"repos_url": "https://api.github.com/users/km5ar/repos",
"events_url": "https://api.github.com/users/km5ar/events{/privacy}",
"received_events_url": "https://api.github.com/users/km5ar/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"FYI @lewtun ",
"Hi @km5ar, thanks for reporting.\r\n\r\nThis should be fixed in the notebook:\r\n- the filename `datasets-issues-with-hf-doc-builder.jsonl` no longer exists on the repo; instead, current filename is `datasets-issues-with-comments.jsonl`\r\n- see: https://huggingface.co/datasets/lewtun/github-issu... | 2022-10-06T19:48:58 | 2022-10-07T15:12:01 | 2022-10-07T15:12:01 | NONE | null | ## Describe the bug
I was following chap 5 from huggingface course: https://huggingface.co/course/chapter5/6?fw=tf
However, I'm not able to download the datasets, with a 404 erros
<img width="1160" alt="iShot2022-10-06_15 54 50" src="https://user-images.githubusercontent.com/54015474/194406327-ae62c2f3-1da5-4686-8631-13d879a0edee.png">
## Steps to reproduce the bug
```python
from huggingface_hub import hf_hub_url
data_files = hf_hub_url(
repo_id="lewtun/github-issues",
filename="datasets-issues-with-hf-doc-builder.jsonl",
repo_type="dataset",
)
from datasets import load_dataset
issues_dataset = load_dataset("json", data_files=data_files, split="train")
issues_dataset
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.2
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.12
- PyArrow version: 9.0.0
- Pandas version: 1.4.4
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5086/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5086/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5085 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5085/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5085/comments | https://api.github.com/repos/huggingface/datasets/issues/5085/events | https://github.com/huggingface/datasets/issues/5085 | 1,400,113,569 | I_kwDODunzps5TdAmh | 5,085 | Filtering on an empty dataset returns a corrupted dataset. | {
"login": "gabegma",
"id": 36087158,
"node_id": "MDQ6VXNlcjM2MDg3MTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/36087158?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gabegma",
"html_url": "https://github.com/gabegma",
"followers_url": "https://api.github.com/users/gabegma/followers",
"following_url": "https://api.github.com/users/gabegma/following{/other_user}",
"gists_url": "https://api.github.com/users/gabegma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gabegma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gabegma/subscriptions",
"organizations_url": "https://api.github.com/users/gabegma/orgs",
"repos_url": "https://api.github.com/users/gabegma/repos",
"events_url": "https://api.github.com/users/gabegma/events{/privacy}",
"received_events_url": "https://api.github.com/users/gabegma/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 4614514401,
"node_id": "LA_kwDODunzps8AAAAB... | closed | false | {
"login": "Mouhanedg56",
"id": 23029765,
"node_id": "MDQ6VXNlcjIzMDI5NzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/23029765?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mouhanedg56",
"html_url": "https://github.com/Mouhanedg56",
"followers_url": "https://api.github.com/users/Mouhanedg56/followers",
"following_url": "https://api.github.com/users/Mouhanedg56/following{/other_user}",
"gists_url": "https://api.github.com/users/Mouhanedg56/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mouhanedg56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mouhanedg56/subscriptions",
"organizations_url": "https://api.github.com/users/Mouhanedg56/orgs",
"repos_url": "https://api.github.com/users/Mouhanedg56/repos",
"events_url": "https://api.github.com/users/Mouhanedg56/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mouhanedg56/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "Mouhanedg56",
"id": 23029765,
"node_id": "MDQ6VXNlcjIzMDI5NzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/23029765?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mouhanedg56",
"html_url": "https://github.com/Mouhanedg56",
"followers_url": "htt... | null | [
"~~It seems like #5043 fix (merged recently) is the root cause of such behaviour. When we empty indices mapping (because the dataset length equals to zero), we can no longer get column item like: `ds_filter_2['sentence']` which uses\r\n`ds_filter_1._indices.column(0)`~~\r\n\r\n**UPDATE:**\r\nEmpty datasets are retu... | 2022-10-06T18:18:49 | 2022-10-07T19:06:02 | 2022-10-07T18:40:26 | NONE | null | ## Describe the bug
When filtering a dataset twice, where the first result is an empty dataset, the second dataset seems corrupted.
## Steps to reproduce the bug
```python
datasets = load_dataset("glue", "sst2")
dataset_split = datasets['validation']
ds_filter_1 = dataset_split.filter(lambda x: False) # Some filtering condition that leads to an empty dataset
assert ds_filter_1.num_rows == 0
sentences = ds_filter_1['sentence']
assert len(sentences) == 0
ds_filter_2 = ds_filter_1.filter(lambda x: False) # Some other filtering condition
assert ds_filter_2.num_rows == 0
assert 'sentence' in ds_filter_2.column_names
sentences = ds_filter_2['sentence']
```
## Expected results
The last line should be returning an empty list, same as 4 lines above.
## Actual results
The last line currently raises `IndexError: index out of bounds`.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.2
- Platform: macOS-11.6.6-x86_64-i386-64bit
- Python version: 3.9.11
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5085/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 3,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5085/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5084 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5084/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5084/comments | https://api.github.com/repos/huggingface/datasets/issues/5084/events | https://github.com/huggingface/datasets/pull/5084 | 1,400,016,229 | PR_kwDODunzps5AVXwm | 5,084 | IterableDataset formatting in numpy/torch/tf/jax | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-06T16:53:38 | 2022-12-20T17:19:52 | 2022-12-20T17:19:52 | MEMBER | null | This code now returns a numpy array:
```python
from datasets import load_dataset
ds = load_dataset("imagenet-1k", split="train", streaming=True).with_format("np")
print(next(iter(ds))["image"])
```
It also works with "arrow", "pandas", "torch", "tf" and "jax"
### Implementation details:
I'm using the existing code to format an Arrow Table to the right output format for simplicity.
Therefore it's probbaly not the most optimized approach.
For example to output PyTorch tensors it does this for every example:
python data -> arrow table -> numpy extracted data -> pytorch formatted data
### Releasing this feature
Even though I consider this as a bug/inconsistency, this change is a breaking change.
And I'm sure some users were relying on the torch iterable dataset to return PIL Image and used data collators to convert to pytorch.
So I guess this is `datasets` 3.0 ?
### TODO
- [x] merge https://github.com/huggingface/datasets/pull/5072
- [ ] docs
- [ ] tests
Close https://github.com/huggingface/datasets/issues/5083 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5084/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5084/timeline | null | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5084",
"html_url": "https://github.com/huggingface/datasets/pull/5084",
"diff_url": "https://github.com/huggingface/datasets/pull/5084.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5084.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5082 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5082/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5082/comments | https://api.github.com/repos/huggingface/datasets/issues/5082/events | https://github.com/huggingface/datasets/pull/5082 | 1,399,379,777 | PR_kwDODunzps5ATJv- | 5,082 | adding keep in memory | {
"login": "Mustapha-AJEGHRIR",
"id": 66799406,
"node_id": "MDQ6VXNlcjY2Nzk5NDA2",
"avatar_url": "https://avatars.githubusercontent.com/u/66799406?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mustapha-AJEGHRIR",
"html_url": "https://github.com/Mustapha-AJEGHRIR",
"followers_url": "https://api.github.com/users/Mustapha-AJEGHRIR/followers",
"following_url": "https://api.github.com/users/Mustapha-AJEGHRIR/following{/other_user}",
"gists_url": "https://api.github.com/users/Mustapha-AJEGHRIR/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mustapha-AJEGHRIR/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mustapha-AJEGHRIR/subscriptions",
"organizations_url": "https://api.github.com/users/Mustapha-AJEGHRIR/orgs",
"repos_url": "https://api.github.com/users/Mustapha-AJEGHRIR/repos",
"events_url": "https://api.github.com/users/Mustapha-AJEGHRIR/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mustapha-AJEGHRIR/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-06T11:10:46 | 2022-10-07T14:35:34 | 2022-10-07T14:32:54 | CONTRIBUTOR | null | Fixing #514 .
Hello @mariosasko 👋, I have implemented what you have recommanded to fix the keep in memory problem for shuffle on the issue #514 . | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5082/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5082/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5082",
"html_url": "https://github.com/huggingface/datasets/pull/5082",
"diff_url": "https://github.com/huggingface/datasets/pull/5082.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5082.patch",
"merged_at": "2022-10-07T14:32:54"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5079 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5079/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5079/comments | https://api.github.com/repos/huggingface/datasets/issues/5079/events | https://github.com/huggingface/datasets/pull/5079 | 1,398,609,305 | PR_kwDODunzps5AQemi | 5,079 | refactor: replace AssertionError with more meaningful exceptions (#5074) | {
"login": "galbwe",
"id": 20004072,
"node_id": "MDQ6VXNlcjIwMDA0MDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/20004072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/galbwe",
"html_url": "https://github.com/galbwe",
"followers_url": "https://api.github.com/users/galbwe/followers",
"following_url": "https://api.github.com/users/galbwe/following{/other_user}",
"gists_url": "https://api.github.com/users/galbwe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/galbwe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/galbwe/subscriptions",
"organizations_url": "https://api.github.com/users/galbwe/orgs",
"repos_url": "https://api.github.com/users/galbwe/repos",
"events_url": "https://api.github.com/users/galbwe/events{/privacy}",
"received_events_url": "https://api.github.com/users/galbwe/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-06T01:39:35 | 2022-10-07T14:35:43 | 2022-10-07T14:33:10 | CONTRIBUTOR | null | Closes #5074
Replaces `AssertionError` in the following files with more descriptive exceptions:
- `src/datasets/arrow_reader.py`
- `src/datasets/builder.py`
- `src/datasets/utils/version.py`
The issue listed more files that needed to be fixed, but the rest of them were contained in the top-level `datasets` directory, which was removed when #4974 was merged | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5079/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5079/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5079",
"html_url": "https://github.com/huggingface/datasets/pull/5079",
"diff_url": "https://github.com/huggingface/datasets/pull/5079.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5079.patch",
"merged_at": "2022-10-07T14:33:10"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5078 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5078/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5078/comments | https://api.github.com/repos/huggingface/datasets/issues/5078/events | https://github.com/huggingface/datasets/pull/5078 | 1,398,335,148 | PR_kwDODunzps5APjkH | 5,078 | Fix header level in Audio docs | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-05T20:22:44 | 2022-10-06T08:12:23 | 2022-10-06T08:09:41 | MEMBER | null | Fixes header level so `Dataset features` is the doc title instead of `The Audio type`:
 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5078/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5078/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5078",
"html_url": "https://github.com/huggingface/datasets/pull/5078",
"diff_url": "https://github.com/huggingface/datasets/pull/5078.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5078.patch",
"merged_at": "2022-10-06T08:09:41"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5077 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5077/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5077/comments | https://api.github.com/repos/huggingface/datasets/issues/5077/events | https://github.com/huggingface/datasets/pull/5077 | 1,398,080,859 | PR_kwDODunzps5AOs9L | 5,077 | Fix passed download_config in HubDatasetModuleFactoryWithoutScript | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-05T16:42:36 | 2022-10-06T05:31:22 | 2022-10-06T05:29:06 | MEMBER | null | Fix passed `download_config` in `HubDatasetModuleFactoryWithoutScript`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5077/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5077/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5077",
"html_url": "https://github.com/huggingface/datasets/pull/5077",
"diff_url": "https://github.com/huggingface/datasets/pull/5077.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5077.patch",
"merged_at": "2022-10-06T05:29:06"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5076 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5076/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5076/comments | https://api.github.com/repos/huggingface/datasets/issues/5076/events | https://github.com/huggingface/datasets/pull/5076 | 1,397,918,092 | PR_kwDODunzps5AOJp7 | 5,076 | fix: update exception throw from OSError to EnvironmentError in `push… | {
"login": "rahulXs",
"id": 29496999,
"node_id": "MDQ6VXNlcjI5NDk2OTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/29496999?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rahulXs",
"html_url": "https://github.com/rahulXs",
"followers_url": "https://api.github.com/users/rahulXs/followers",
"following_url": "https://api.github.com/users/rahulXs/following{/other_user}",
"gists_url": "https://api.github.com/users/rahulXs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rahulXs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rahulXs/subscriptions",
"organizations_url": "https://api.github.com/users/rahulXs/orgs",
"repos_url": "https://api.github.com/users/rahulXs/repos",
"events_url": "https://api.github.com/users/rahulXs/events{/privacy}",
"received_events_url": "https://api.github.com/users/rahulXs/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-05T14:46:29 | 2022-10-07T14:35:57 | 2022-10-07T14:33:27 | CONTRIBUTOR | null | Status:
Ready for review
Description of Changes:
Fixes #5075
Changes proposed in this pull request:
- Throw EnvironmentError instead of OSError in `push_to_hub` when the Hub token is not present. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5076/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5076/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5076",
"html_url": "https://github.com/huggingface/datasets/pull/5076",
"diff_url": "https://github.com/huggingface/datasets/pull/5076.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5076.patch",
"merged_at": "2022-10-07T14:33:27"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5075 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5075/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5075/comments | https://api.github.com/repos/huggingface/datasets/issues/5075/events | https://github.com/huggingface/datasets/issues/5075 | 1,397,865,501 | I_kwDODunzps5TUbwd | 5,075 | Throw EnvironmentError when token is not present | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
},
{
"id": 4614514401,
"node_... | closed | false | null | [] | null | [
"@mariosasko I've raised a PR #5076 against this issue. Please help to review. Thanks."
] | 2022-10-05T14:14:18 | 2022-10-07T14:33:28 | 2022-10-07T14:33:28 | CONTRIBUTOR | null | Throw EnvironmentError instead of OSError ([link](https://github.com/huggingface/datasets/blob/6ad430ba0cdeeb601170f732d4bd977f5c04594d/src/datasets/arrow_dataset.py#L4306) to the line) in `push_to_hub` when the Hub token is not present. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5075/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5075/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5074 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5074/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5074/comments | https://api.github.com/repos/huggingface/datasets/issues/5074/events | https://github.com/huggingface/datasets/issues/5074 | 1,397,850,352 | I_kwDODunzps5TUYDw | 5,074 | Replace AssertionErrors with more meaningful errors | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
},
{
"id": 4614514401,
"node_... | closed | false | {
"login": "galbwe",
"id": 20004072,
"node_id": "MDQ6VXNlcjIwMDA0MDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/20004072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/galbwe",
"html_url": "https://github.com/galbwe",
"followers_url": "https://api.github.com/users/galbwe/followers",
"following_url": "https://api.github.com/users/galbwe/following{/other_user}",
"gists_url": "https://api.github.com/users/galbwe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/galbwe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/galbwe/subscriptions",
"organizations_url": "https://api.github.com/users/galbwe/orgs",
"repos_url": "https://api.github.com/users/galbwe/repos",
"events_url": "https://api.github.com/users/galbwe/events{/privacy}",
"received_events_url": "https://api.github.com/users/galbwe/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "galbwe",
"id": 20004072,
"node_id": "MDQ6VXNlcjIwMDA0MDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/20004072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/galbwe",
"html_url": "https://github.com/galbwe",
"followers_url": "https://api.github... | null | [
"Hi, can I pick up this issue?",
"#self-assign",
"Looks like the top-level `datasource` directory was removed when https://github.com/huggingface/datasets/pull/4974 was merged, so there are 3 source files to fix."
] | 2022-10-05T14:03:55 | 2022-10-07T14:33:11 | 2022-10-07T14:33:11 | CONTRIBUTOR | null | Replace the AssertionErrors with more meaningful errors such as ValueError, TypeError, etc.
The files with AssertionErrors that need to be replaced:
```
src/datasets/arrow_reader.py
src/datasets/builder.py
src/datasets/utils/version.py
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5074/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5074/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5073 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5073/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5073/comments | https://api.github.com/repos/huggingface/datasets/issues/5073/events | https://github.com/huggingface/datasets/pull/5073 | 1,397,832,183 | PR_kwDODunzps5AN3Gn | 5,073 | Restore saved format state in `load_from_disk` | {
"login": "asofiaoliveira",
"id": 74454835,
"node_id": "MDQ6VXNlcjc0NDU0ODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/74454835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asofiaoliveira",
"html_url": "https://github.com/asofiaoliveira",
"followers_url": "https://api.github.com/users/asofiaoliveira/followers",
"following_url": "https://api.github.com/users/asofiaoliveira/following{/other_user}",
"gists_url": "https://api.github.com/users/asofiaoliveira/gists{/gist_id}",
"starred_url": "https://api.github.com/users/asofiaoliveira/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/asofiaoliveira/subscriptions",
"organizations_url": "https://api.github.com/users/asofiaoliveira/orgs",
"repos_url": "https://api.github.com/users/asofiaoliveira/repos",
"events_url": "https://api.github.com/users/asofiaoliveira/events{/privacy}",
"received_events_url": "https://api.github.com/users/asofiaoliveira/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-05T13:51:47 | 2022-10-11T16:55:07 | 2022-10-11T16:49:23 | CONTRIBUTOR | null | Hello! @mariosasko
This pull request relates to issue #5050 and intends to add the format to datasets loaded from disk.
All I did was add a set_format in the Dataset.load_from_disk, as DatasetDict.load_from_disk relies on the first.
I don't know if I should add a test and where, so let me know if I should and I can work on that as well!
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5073/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5073/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5073",
"html_url": "https://github.com/huggingface/datasets/pull/5073",
"diff_url": "https://github.com/huggingface/datasets/pull/5073.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5073.patch",
"merged_at": "2022-10-11T16:49:23"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5072 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5072/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5072/comments | https://api.github.com/repos/huggingface/datasets/issues/5072/events | https://github.com/huggingface/datasets/pull/5072 | 1,397,765,531 | PR_kwDODunzps5ANoo5 | 5,072 | Image & Audio formatting for numpy/torch/tf/jax | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-05T13:07:03 | 2022-10-10T13:24:10 | 2022-10-10T13:21:32 | MEMBER | null | Added support for image and audio formatting for numpy, torch, tf and jax.
For images, the dtype used is the one of the image (the one returned by PIL.Image), e.g. uint8
I also added support for string, binary and None types. In particular for torch and jax, strings are kept unchanged (previously it was returning an error because you can't create a tensor of strings) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5072/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5072/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5072",
"html_url": "https://github.com/huggingface/datasets/pull/5072",
"diff_url": "https://github.com/huggingface/datasets/pull/5072.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5072.patch",
"merged_at": "2022-10-10T13:21:32"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5071 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5071/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5071/comments | https://api.github.com/repos/huggingface/datasets/issues/5071/events | https://github.com/huggingface/datasets/pull/5071 | 1,397,301,270 | PR_kwDODunzps5AMG3g | 5,071 | Support DEFAULT_CONFIG_NAME when no BUILDER_CONFIGS | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-05T06:28:39 | 2022-10-06T14:43:12 | 2022-10-06T14:40:26 | MEMBER | null | This PR supports defining a default config name, even if no predefined allowed config names are set.
Fix #5070.
CC: @stas00 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5071/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5071/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5071",
"html_url": "https://github.com/huggingface/datasets/pull/5071",
"diff_url": "https://github.com/huggingface/datasets/pull/5071.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5071.patch",
"merged_at": "2022-10-06T14:40:25"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5070 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5070/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5070/comments | https://api.github.com/repos/huggingface/datasets/issues/5070/events | https://github.com/huggingface/datasets/issues/5070 | 1,396,765,647 | I_kwDODunzps5TQPPP | 5,070 | Support default config name when no builder configs | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Thank you for creating this feature request, Albert.\r\n\r\nFor context this is the datatest where Albert has been helping me to switch to on-the-fly split config https://huggingface.co/datasets/HuggingFaceM4/cm4-synthetic-testing\r\n\r\nand the attempt to switch on-the-fly splits was here: https://huggingface.co/... | 2022-10-04T19:49:35 | 2022-10-06T14:40:26 | 2022-10-06T14:40:26 | MEMBER | null | **Is your feature request related to a problem? Please describe.**
As discussed with @stas00, we could support defining a default config name, even if no predefined allowed config names are set. That is, support `DEFAULT_CONFIG_NAME`, even when `BUILDER_CONFIGS` is not defined.
**Additional context**
In order to support creating configs on the fly **by name** (not using kwargs), the list of allowed builder configs `BUILDER_CONFIGS` must not be set.
However, if so, then `DEFAULT_CONFIG_NAME` is not supported.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5070/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5070/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5067 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5067/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5067/comments | https://api.github.com/repos/huggingface/datasets/issues/5067/events | https://github.com/huggingface/datasets/pull/5067 | 1,396,361,768 | PR_kwDODunzps5AI86d | 5,067 | Fix CONTRIBUTING once dataset scripts transferred to Hub | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-04T14:16:05 | 2022-10-06T06:14:43 | 2022-10-06T06:12:12 | MEMBER | null | This PR updates the `CONTRIBUTING.md` guide, once the all dataset scripts have been removed from the GitHub repo and transferred to the HF Hub:
- #4974
See diff here: https://github.com/huggingface/datasets/commit/e3291ecff9e54f09fcee3f313f051a03fdc3d94b
Additionally, this PR fixes the line separator that by some previous mistake was CRLF instead of LF. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5067/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5067/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5067",
"html_url": "https://github.com/huggingface/datasets/pull/5067",
"diff_url": "https://github.com/huggingface/datasets/pull/5067.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5067.patch",
"merged_at": "2022-10-06T06:12:12"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5066 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5066/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5066/comments | https://api.github.com/repos/huggingface/datasets/issues/5066/events | https://github.com/huggingface/datasets/pull/5066 | 1,396,086,745 | PR_kwDODunzps5AIDWj | 5,066 | Support streaming gzip.open | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-04T11:20:05 | 2022-10-06T15:13:51 | 2022-10-06T15:11:29 | MEMBER | null | This PR implements support for streaming out-of-the-box dataset scripts containing `gzip.open`.
This has been a recurring issue. See, e.g.:
- #5060
- #3191 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5066/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5066/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5066",
"html_url": "https://github.com/huggingface/datasets/pull/5066",
"diff_url": "https://github.com/huggingface/datasets/pull/5066.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5066.patch",
"merged_at": "2022-10-06T15:11:29"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5065 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5065/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5065/comments | https://api.github.com/repos/huggingface/datasets/issues/5065/events | https://github.com/huggingface/datasets/pull/5065 | 1,396,003,362 | PR_kwDODunzps5AHxlQ | 5,065 | Ci py3.10 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-04T10:13:51 | 2022-11-29T15:28:05 | 2022-11-29T15:25:26 | MEMBER | null | Added a CI job for python 3.10
Some dependencies don't work on 3.10 like apache beam, so I remove them from the extras in this case.
I also removed some s3 fixtures that we don't use anymore (and that don't work on 3.10 anyway) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5065/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5065/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5065",
"html_url": "https://github.com/huggingface/datasets/pull/5065",
"diff_url": "https://github.com/huggingface/datasets/pull/5065.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5065.patch",
"merged_at": "2022-11-29T15:25:26"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5064 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5064/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5064/comments | https://api.github.com/repos/huggingface/datasets/issues/5064/events | https://github.com/huggingface/datasets/pull/5064 | 1,395,978,143 | PR_kwDODunzps5AHsP0 | 5,064 | Align signature of create/delete_repo with latest hfh | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-04T09:54:53 | 2022-10-07T17:02:11 | 2022-10-07T16:59:30 | MEMBER | null | This PR aligns the signature of `create_repo`/`delete_repo` with the current one in hfh, by removing deprecated `name` and `organization`, and using `repo_id` instead.
Related to:
- #5063
CC: @lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5064/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5064/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5064",
"html_url": "https://github.com/huggingface/datasets/pull/5064",
"diff_url": "https://github.com/huggingface/datasets/pull/5064.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5064.patch",
"merged_at": "2022-10-07T16:59:30"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5063 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5063/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5063/comments | https://api.github.com/repos/huggingface/datasets/issues/5063/events | https://github.com/huggingface/datasets/pull/5063 | 1,395,895,463 | PR_kwDODunzps5AHasG | 5,063 | Align signature of list_repo_files with latest hfh | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-04T08:51:46 | 2022-10-07T16:42:57 | 2022-10-07T16:40:16 | MEMBER | null | This PR aligns the signature of `list_repo_files` with the current one in `hfh`, by renaming deprecated `token` to `use_auth_token`.
This is already the case for `dataset_info`.
CC: @lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5063/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5063/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5063",
"html_url": "https://github.com/huggingface/datasets/pull/5063",
"diff_url": "https://github.com/huggingface/datasets/pull/5063.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5063.patch",
"merged_at": "2022-10-07T16:40:16"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5062 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5062/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5062/comments | https://api.github.com/repos/huggingface/datasets/issues/5062/events | https://github.com/huggingface/datasets/pull/5062 | 1,395,739,417 | PR_kwDODunzps5AG6SA | 5,062 | Fix CI hfh token warning | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-04T06:36:54 | 2022-10-04T08:58:15 | 2022-10-04T08:42:31 | MEMBER | null | In our CI, we get warnings from `hfh` about using deprecated `token`: https://github.com/huggingface/datasets/actions/runs/3174626525/jobs/5171672431
```
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_private
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_multiple_files
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_multiple_files_with_max_shard_size
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_overwrite_files
C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\site-packages\huggingface_hub\utils\_deprecation.py:97: FutureWarning: Deprecated argument(s) used in 'dataset_info': token. Will not be supported from version '0.12'.
warnings.warn(message, FutureWarning)
```
This PR fixes the tests in `TestPushToHub` so that we fix these warnings.
Continuation of:
- #5031
CC: @lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5062/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5062/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5062",
"html_url": "https://github.com/huggingface/datasets/pull/5062",
"diff_url": "https://github.com/huggingface/datasets/pull/5062.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5062.patch",
"merged_at": "2022-10-04T08:42:31"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5060 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5060/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5060/comments | https://api.github.com/repos/huggingface/datasets/issues/5060/events | https://github.com/huggingface/datasets/issues/5060 | 1,395,382,940 | I_kwDODunzps5TK9qc | 5,060 | Unable to Use Custom Dataset Locally | {
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! I opened a PR in your repo to fix this :)\r\nhttps://huggingface.co/datasets/zpn/pubchem_selfies/discussions/7\r\n\r\nbasically you need to use `open` for streaming to work properly",
"Thank you so much for this! Naive question, is this a feature of `open` or have you all overloaded it to be able to read fr... | 2022-10-03T21:55:16 | 2022-10-06T14:29:18 | 2022-10-06T14:29:17 | CONTRIBUTOR | null | ## Describe the bug
I have uploaded a [dataset](https://huggingface.co/datasets/zpn/pubchem_selfies) and followed the instructions from the [dataset_loader](https://huggingface.co/docs/datasets/dataset_script#download-data-files-and-organize-splits) tutorial. In that tutorial, it says
```
If the data files live in the same folder or repository of the dataset script,
you can just pass the relative paths to the files instead of URLs.
```
Accordingly, I put the [relative path](https://huggingface.co/datasets/zpn/pubchem_selfies/blob/main/pubchem_selfies.py#L76) to the data to be used. I was able to test the dataset and generate the metadata locally with `datasets-cli test path/to/<your-dataset-loading-script> --save_infos --all_configs`
However, if I try to load the data using `load_dataset`, I get the following error
```
with gzip.open(filepath, mode="rt") as f:
File "/usr/local/Cellar/python@3.9/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/gzip.py", line 58, in open
binary_file = GzipFile(filename, gz_mode, compresslevel)
File "/usr/local/Cellar/python@3.9/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/gzip.py", line 173, in __init__
fileobj = self.myfileobj = builtins.open(filename, mode or 'rb')
FileNotFoundError: [Errno 2] No such file or directory: 'https://huggingface.co/datasets/zpn/pubchem_selfies/resolve/main/data/Compound_021000001_021500000/Compound_021000001_021500000_SELFIES.jsonl.gz'
```
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("zpn/pubchem_selfies", streaming=True)
>>> t = dataset["train"]
>>> for item in t:
...... print(item)
...... break
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/zachnussbaum/env/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 723, in __iter__
for key, example in self._iter():
File "/Users/zachnussbaum/env/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 713, in _iter
yield from ex_iterable
File "/Users/zachnussbaum/env/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 113, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/Users/zachnussbaum/.cache/huggingface/modules/datasets_modules/datasets/zpn--pubchem_selfies/d2571f35996765aea70fd3f3f8e3882d59c401fb738615c79282e2eb1d9f7a25/pubchem_selfies.py", line 475, in _generate_examples
with gzip.open(filepath, mode="rt") as f:
File "/usr/local/Cellar/python@3.9/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/gzip.py", line 58, in open
binary_file = GzipFile(filename, gz_mode, compresslevel)
File "/usr/local/Cellar/python@3.9/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/gzip.py", line 173, in __init__
fileobj = self.myfileobj = builtins.open(filename, mode or 'rb')
FileNotFoundError: [Errno 2] No such file or directory: 'https://huggingface.co/datasets/zpn/pubchem_selfies/resolve/main/data/Compound_021000001_021500000/Compound_021000001_021500000_SELFIES.jsonl.gz'
````
```
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.1
- Platform: macOS-12.5.1-x86_64-i386-64bit
- Python version: 3.9.7
- PyArrow version: 9.0.0
- Pandas version: 1.5.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5060/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5060/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5059 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5059/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5059/comments | https://api.github.com/repos/huggingface/datasets/issues/5059/events | https://github.com/huggingface/datasets/pull/5059 | 1,395,050,876 | PR_kwDODunzps5AEoX7 | 5,059 | Fix typo | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-03T17:05:25 | 2022-10-03T17:34:40 | 2022-10-03T17:32:27 | MEMBER | null | Fixes a small typo :) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5059/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5059/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5059",
"html_url": "https://github.com/huggingface/datasets/pull/5059",
"diff_url": "https://github.com/huggingface/datasets/pull/5059.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5059.patch",
"merged_at": "2022-10-03T17:32:27"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5058 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5058/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5058/comments | https://api.github.com/repos/huggingface/datasets/issues/5058/events | https://github.com/huggingface/datasets/pull/5058 | 1,394,962,424 | PR_kwDODunzps5AEVWn | 5,058 | Mark CI tests as xfail when 502 error | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-03T15:53:55 | 2022-10-04T10:03:23 | 2022-10-04T10:01:23 | MEMBER | null | To make CI more robust, we could mark as xfail when the Hub raises a 502 error (besides 500 error):
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_to_hub_skip_identical_files
- https://github.com/huggingface/datasets/actions/runs/3174626525/jobs/5171672431
```
> raise HTTPError(http_error_msg, response=self)
E requests.exceptions.HTTPError: 502 Server Error: Bad Gateway for url: https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16648055339047.git/info/lfs/objects/batch
```
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_overwrite_files
- https://github.com/huggingface/datasets/actions/runs/3145587033/jobs/5113074889
```
> raise HTTPError(http_error_msg, response=self)
E requests.exceptions.HTTPError: 502 Server Error: Bad Gateway for url: https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16643866807322.git/info/lfs/objects/verify
```
Currently, we mark as xfail when 500 error:
- #4845 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5058/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5058/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5058",
"html_url": "https://github.com/huggingface/datasets/pull/5058",
"diff_url": "https://github.com/huggingface/datasets/pull/5058.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5058.patch",
"merged_at": "2022-10-04T10:01:23"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/5057 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5057/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5057/comments | https://api.github.com/repos/huggingface/datasets/issues/5057/events | https://github.com/huggingface/datasets/pull/5057 | 1,394,827,216 | PR_kwDODunzps5AD4c6 | 5,057 | Support `converters` in `CsvBuilder` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2022-10-03T14:23:21 | 2022-10-04T11:19:28 | 2022-10-04T11:17:32 | CONTRIBUTOR | null | Add the `converters` param to `CsvBuilder`, to help in situations like [this one](https://discuss.huggingface.co/t/typeerror-in-load-dataset-related-to-a-sequence-of-strings/23545).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5057/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5057/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5057",
"html_url": "https://github.com/huggingface/datasets/pull/5057",
"diff_url": "https://github.com/huggingface/datasets/pull/5057.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5057.patch",
"merged_at": "2022-10-04T11:17:32"
} | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.