
YAML Metadata Warning:empty or missing yaml metadata in repo card
Check out the documentation for more information.
ML Debug Env: Teaching AI Agents to Debug Like Engineers, Not Oracles
Built for the Meta × PyTorch × Scaler OpenEnv Hackathon — April 2026
📝 This is the submission blog post for ML Debug Env — Meta × PyTorch × Scaler OpenEnv Hackathon 2026
The Problem
Every ML engineer has stared at a broken training script. Sometimes it crashes with an explicit error. Sometimes loss quietly explodes to NaN. Sometimes the model trains perfectly, reports 96% accuracy, and the evaluation is completely invalid.
Debugging is not about knowing the answer. It's about gathering evidence — running the code, reading tracebacks, checking gradient norms, forming a hypothesis, and fixing.
We built an environment that trains AI agents to do exactly this.
What We Built
ML Debug Env is a partially observable reinforcement learning environment where agents debug broken PyTorch training scripts. Built on OpenEnv.
The key design decision: the agent starts blind.
On reset(), the agent receives only a minimal alert — the kind of message an on-call engineer sees at 2am:
"Training job failed. Final loss: nan."
No buggy code. No traceback. No hints. Just a failure notice and a set of diagnostic tools.
The agent must then decide what to investigate using a 5-step budget:
| Tool | What it returns |
|---|---|
run_code |
Runs the buggy script, returns stdout/stderr |
get_traceback |
Returns full traceback if code crashed |
inspect_gradients |
Injects gradient norm logging, runs one batch |
print_shapes |
Injects shape hooks, returns tensor dims at each layer |
view_source |
Reveals the full buggy script (costs 1 step) |
After gathering evidence, the agent submits a fix — a complete corrected Python script. The grader actually executes the fixed code in a subprocess. No regex matching. No shortcuts. The code has to run.
The Tasks
Eight tasks of increasing difficulty, covering the most common classes of real PyTorch bugs:
| Task | Difficulty | What's Broken |
|---|---|---|
shape_mismatch |
Easy | nn.Linear input dim wrong → explicit crash |
training_collapse |
Medium | Bad LR → NaN loss, or wrong loss fn → plateau |
wrong_device |
Medium | Model on GPU, data on CPU → explicit crash |
gradient_not_zeroed |
Medium-Hard | Missing zero_grad() → loss explodes silently |
data_leakage |
Hard | Normalized before split → metrics look great but invalid |
missing_eval_mode |
Hard | No model.eval() → non-deterministic metrics |
compound_shape_device |
Medium-Hard | TWO bugs: shape mismatch + device mismatch |
compound_leakage_eval |
Expert | TWO bugs: data leakage + missing eval mode |
The compound tasks are the hardest — the agent must find and fix two independent bugs simultaneously, both silent, neither causing a crash.
Scoring
Six-stage partial credit ladder:
0.01 → Wrong bug type identified
0.20 → Right type, fixed code crashes
0.40 → Code runs, training doesn't complete
0.60 → Training completes, root cause not fixed
0.80 → Root cause fixed, success signal not confirmed
0.99 → Perfect fix — code runs, training finishes, signal confirmed
Plus an efficiency multiplier: fix correctly in ≤2 steps → score ×1.2. This rewards agents that learn to inspect efficiently rather than brute-forcing view_source on every task.
An LLM judge (Groq / llama-3.3-70b) additionally scores the agent's diagnosis on root cause correctness, mechanistic explanation, and specificity — adding up to 0.15 reasoning reward on top of execution reward.
Adaptive Curriculum
An AdversarialScheduler tracks per-task performance across episodes. Bug types where the agent consistently scores below 0.6 are marked "weak." Future reset() calls serve weak tasks 70% of the time with random seeds (novel code variants), and strong tasks only 30% of the time. The environment gets harder as the agent improves — exactly like the adversarial designer pattern from Kube SRE Gym.
Training with GRPO
We trained Qwen2.5-1.5B-Instruct using GRPO (Group Relative Policy Optimization) with LoRA (4-bit, rank 16) on the environment.
Baseline (untrained model):
- Immediately calls
view_sourceon almost every task — brute force pattern - Scores ~0.15 average across all tasks
- Scores 0.0 on
compound_leakage_eval— tries to inspect but can't complete the workflow
After GRPO training (venue compute — A100, 500 steps):
- T4 baseline run (200 steps): Initial reward 0.024 → Final reward 0.190 (+0.166 improvement)
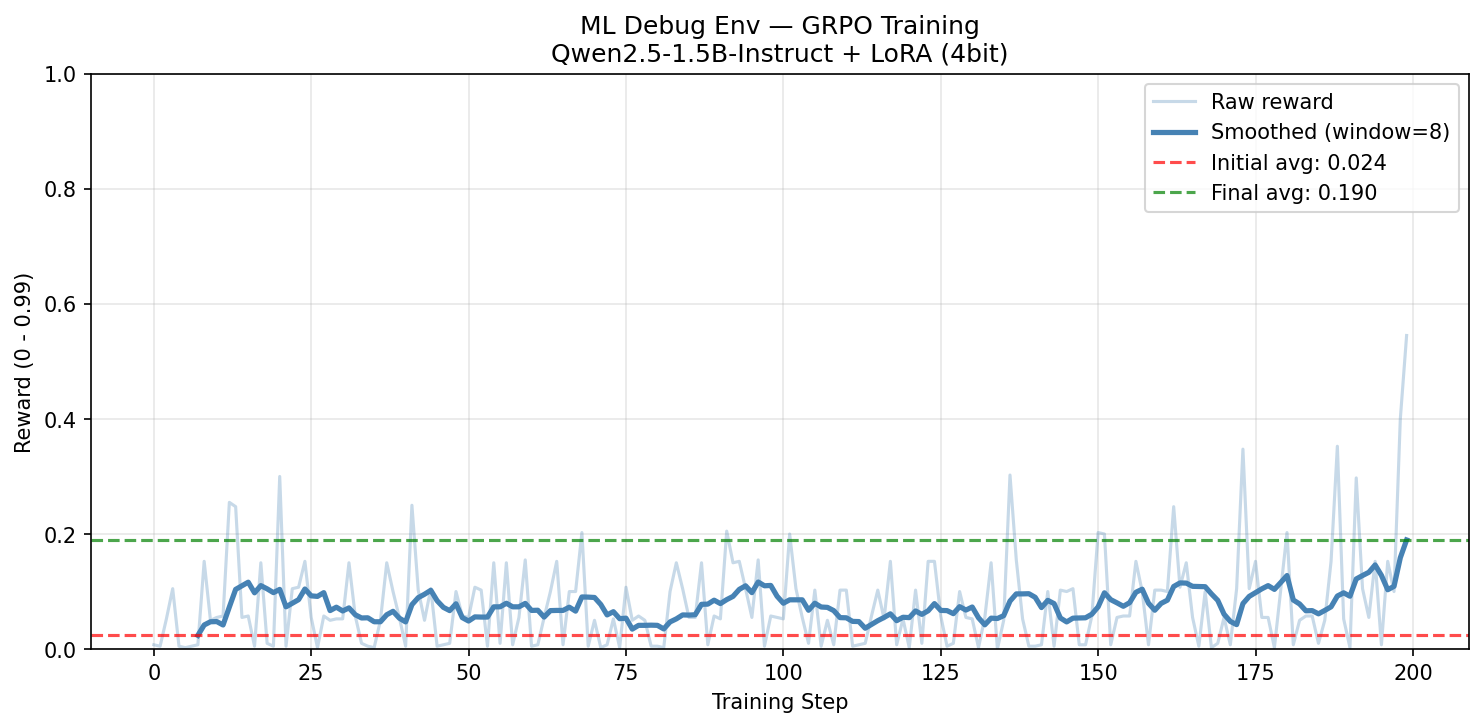
At venue on H100 compute: 500 steps, full reward curve to be added here.
- Agent learns to call
run_code→inspect_gradientsbefore viewing source - Compound tasks show steeper improvement curve — harder tasks provide stronger gradient signal
The emergent inspection strategy shift — from brute-force view_source to evidence-based run_code + inspect_gradients — is the behavior the reward signal shaped. The agent learned it without being told.
Architecture
Agent
│
│ reset() → alert only (no code)
▼
FastAPI Server (OpenEnv)
│
├── inspect action → execute_tool() → tool output
│ run_code, get_traceback, inspect_gradients,
│ print_shapes, view_source
│
├── fix action → Grader.grade()
│ subprocess.run(fixed_code)
│ 6-stage scoring + LLM judge
│ efficiency multiplier (1.0–1.2×)
│
└── AdversarialScheduler
tracks weak tasks → skews future resets
random seeds for novel variants
Links
- HuggingFace Space: https://huggingface.co/spaces/rak2315/ml-debug-env
- GitHub: https://github.com/RAK2315/ml-debug-env
- Training Notebook: https://github.com/RAK2315/ml-debug-env/blob/main/ml_debug_env_grpo.ipynb
What's Next
The inspection tool system is the foundation for a much harder environment. Future work:
- Multi-file debugging (bug spans across data pipeline + model definition)
- Runtime tool calls mid-training (agent can inject print statements and rerun)
- Compound bugs with 3+ independent failures
- Agent-generated bug variants for truly infinite curriculum